PHP и UTF-8
Если на одной через зад через расширения вроде mbstring. Признать такой способ удачным и универсальным нельзя.
Проблема состоит в том, что обычные функции для обработки строк, вроде strlen, используют принцип «один байт — один символ». Поэтому, если им передать строку, в которой некоторые символы закодированы несколькими байтами, могут произойти всякие неприятности.
Однако, если посмотреть на способ кодирования символов в
Одна из редких ситуаций, в которых стандартных функций будет недостаточно, возникает тогда, когда от
if (!function_exists('mb_internal_encoding'))
{
function mb_strlen($str)
{
for ($i = strlen($str), $j = 0; $i--; )
if ((ord($str[$i]) & 0xc0) != 0x80)
$j++;
return $j;
}
function mb_substr($str, $from, $len = false)
{
if ($from >= 0)
{
for ($c_byte = 0; $from--; )
if (ord($str[$c_byte]) <= 0x7F)
$c_byte++;
else
while ((ord($str[++$c_byte]) & 0xc0) == 0x80);
$byte_beg = $c_byte;
if ($len === false)
return substr($str, $byte_beg);
elseif ($len < 0)
{
for ($c_byte = strlen($str) - 1; $len++; $c_byte--)
if (ord($str[$c_byte]) > 0x7F)
while ((ord($str[--$c_byte]) & 0xc0) == 0x80);
return substr($str, $byte_beg, -strlen($str) + 1 + $c_byte);
}
else
{
for ( ; $len--; )
if (ord($str[$c_byte]) <= 0x7F)
$c_byte++;
else
while ((ord($str[++$c_byte]) & 0xc0) == 0x80);
return substr($str, $byte_beg, $c_byte - $byte_beg);
}
}
else
{
$last_byte = strlen($str) - 1;
for ($c_byte = $last_byte; $from++; $c_byte--)
if (ord($str[$c_byte]) > 0x7F)
while ((ord($str[--$c_byte]) & 0xc0) == 0x80);
$byte_beg = $c_byte;
if ($len === false)
return substr($str, $byte_beg - $last_byte);
elseif ($len < 0)
{
for ($c_byte = $last_byte; $len++; $c_byte--)
if (ord($str[$c_byte]) > 0x7F)
while ((ord($str[--$c_byte]) & 0xc0) == 0x80);
return substr($str, $byte_beg - $last_byte, $c_byte - $last_byte);
}
else
{
for ( ; $len--; )
if (ord($str[$c_byte]) <= 0x7F)
$c_byte++;
else
while ((ord($str[++$c_byte]) & 0xc0) == 0x80);
return substr($str, $byte_beg - $last_byte, $c_byte - $byte_beg);
}
}
}
}
else
mb_internal_encoding('UTF-8');
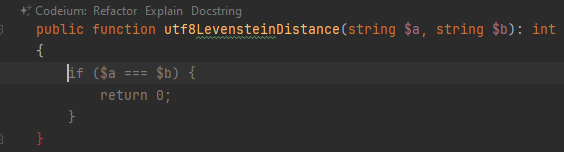
Теперь, чтобы взять первые 10 символов строки, достаточно написать mb_substr($str, 0, 10);.
Вот, в принципе, и всё. В следующей версии SiteX'а основной кодировкой будет

Комментарии
function mb_strlen($str) {
return strlen(preg_replace('#[\x80-\xBF]#s','',$str));
}
На самом деле, мне сначала понадобилась функция utf8_substr. Вариант с регулярными выражениями для малых входных параметров (именно такие мне были нужны) работал медленнее, чем с циклом. Поэтому в utf8_strlen я оставил цикл.
Я исправлю заметку.
Чтобы быть более конкретным, скажу, что речь шла об укорачивании слишком длинных ссылок:
Сейчас там используется другой велосипед:
У меня нет никакого желания выяснять, какой из велосипедов быстрее :)
Оставьте свой комментарий