веб-разработка
HTML, CSS, JS и другие технологии, на которых работают сайты.
Статьи по этой теме:
Латех и
RSS, формулы и Feedly
Постоянные читатели помнят, что у меня есть сервис по превращению математических формул в картинки и редактор для создания математических текстов. С заменой формул на картинки на обычных
Еще в 2011 году я стал отдавать в RSS растровые картинки, потому что непонятно, в каком окружении будет отображаться контент оттуда. А на обычных
Когда в 2013 году прекратила работать
У Feedly была одна особенность с отображением картинок: они принудительно становились плавающими (включалось
Сейчас я решил проверить, не научился ли Feedly отображать нормально картинки. Оказалось, что научился. Если вы читаете этот текст через RSS в Feedly, можете в этом убедиться в предыдущем абзаце.
Чтобы два раза не вставать, я попросил ChatGPT составить
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<head>
<title><xsl:value-of select="rss/channel/title" /></title>
<style type="text/css">
a {
color: #56d;
text-decoration-thickness: 1px;
text-decoration-color: rgba(85, 102, 221, 0.5);
}
body {
max-width: 720px;
font: 16px/1.5 sans-serif;
margin: 0 auto;
}
h1, h2, h3 {
margin: 1em 0 0.25em;
}
p {
margin: 0 0 0.75em;
}
</style>
</head>
<body>
<h1>
<a href="{rss/channel/link}">
<xsl:value-of select="rss/channel/title" />
</a>
</h1>
<xsl:for-each select="rss/channel/item">
<div class="item">
<h2><a href="{link}"><xsl:value-of select="title" /></a></h2>
<div><xsl:value-of select="description" disable-output-escaping="yes" /></div>
</div>
</xsl:for-each>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Чтобы это заработало, нужно добавить ссылку на такой
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet href="/_styles/rss.xslt" type="text/xsl"?>
<rss version="2.0">
<channel>
...
</channel>
</rss>
Кстати, пока со всем этим возился, обнаружил, что в RSS сломалось отображение исходного кода: перестало работать сохранение переносов строк внутри тегов <pre><code>. Долго пытался понять, где ошибка, пока не осознал, что это сломался сам Feedly. Похоже, эта проблема наблюдается в любых источниках в Feedly за последние недели две. Заодно сейчас и проверим, нормально ли будет отформатирован код в этой заметке.
В заключение полезный совет: если хотите отладить RSS и не хотите ждать, пока Feedly проиндексирует новую запись, можете на экране добавления нового источника добавить в URL не меняющую смысла часть запроса. Тогда Feedly распарсит RSS на лету и отобразит три последних записи:
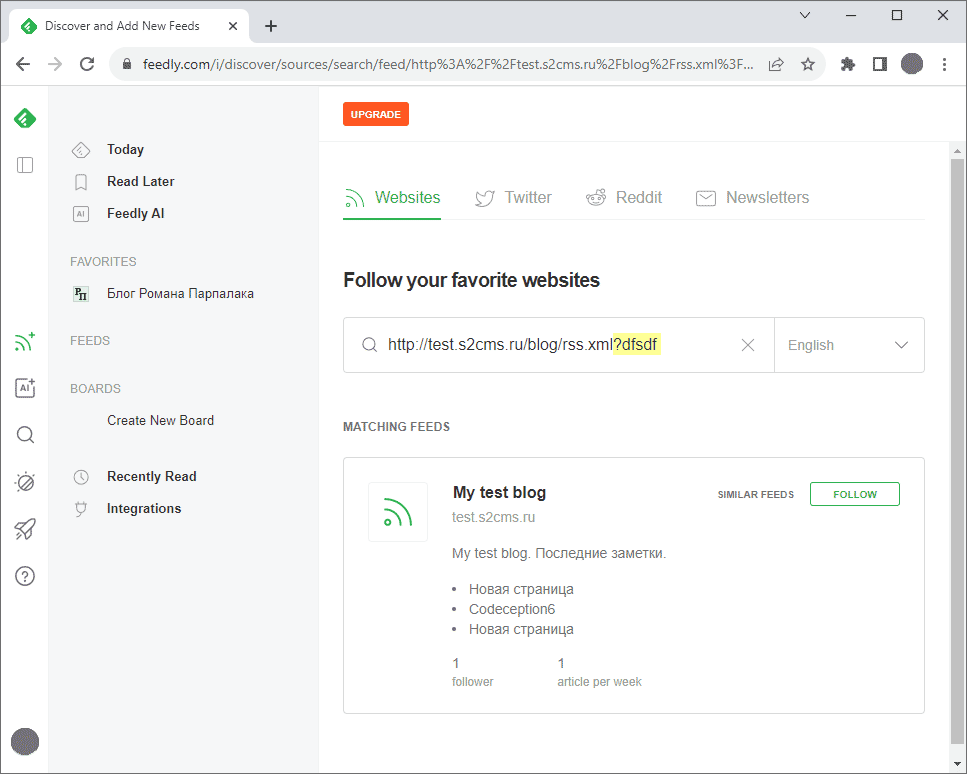
Добавлено позднее: оказывается, Feedly нормально отображает картинки только в
Отложенная загрузка картинок через атрибут lazyload
Оказывается, в браузерах уже есть встроенная поддержка «ленивой» загрузки картинок: далекие от видимой области сайта картинки даже не начинают скачиваться. За это отвечает атрибут loading="lazy" у тега img. Цель простая — экономия трафика. Раньше для ее достижения приходилось писать логику на js. Но встроенная в браузер поддержка, конечно, должна работать точнее.
Чтобы определение области видимости работало правильно, у картинок должны быть прописаны размеры (width и height). Но вообще их и так надо было прописывать, чтобы избежать «эффекта упячки».
Думаю, этот атрибут есть смысл всегда использовать для картинок из основного содержимого. По крайней мере, я не вижу недостатков, если так делать. Добавил в S2 автоматическое добавление атрибута loading="lazy" для загружаемых картинок. Посмотрим, как будет работать, может
Запрет висячих заголовков в CSS
Пару лет назад я сделал стили для печати в своем редакторе математических текстов Upmath. Тогда же я отмечал проблемы подхода, в частности, «висячие заголовки». Не уверен, что такой термин существует, под ним я имею в виду заголовок, расположенный последним на странице и оторванный от следующего текста.
В CSS есть свойства, которые управляют запретом на разбиение страниц. Но мне так и не удалось заставить их работать. Я предположил, что это баг в браузерах, и добавил в трекер периодически всплывающую задачу «проверить запрет разбиения страницы после заголовка». Наконец, сегодня проверка показала, что в Хроме свойства заработали!
Есть два варианта синтаксиса, сейчас работают оба:
h1, h2, h3 {
page-break-after: avoid;
break-after: avoid;
}Результат применения выглядит так (было — стало):

Проверил еще Firefox, в нем запрет разбиения не заработал. А больше
Воспринимайте слова в переписке буквально
В общении между людьми есть проблема недопонимания. Говорящий не всегда правильно подбирает слова, а слушающий додумывает. Иногда получается, что имели в виду одно, сказали другое, а поняли третье.
В устном общении есть возможность задать уточняющий вопрос, и проблема часто снимается. В переписке с этим сложнее, поэтому особенно важно следить за словами: проверять, правильно ли слова передают смысл, и воспринимать слова буквально.
Смотрите, что получается, если
Во всех адресах и примерах использования «https:»почему-то исчезло. Так что адреса формально неправильные.
Чтобы не отправлять вас по ссылкам, поясню, что сервис предлагает УРЛы картинок в виде //i.upmath.me/svg/f(x) и код встраивания скрипта <script src="//i.upmath.me/latex.js"></script>.
Дело в том, что схема (http или https для веба) — необязательная часть адреса, его можно опустить (см.
Посетитель вложил в свою мысль целых два неверных утверждения. Первое: https
Если бы посетитель спросил, почему так сделано, я бы ответил, и может быть даже погуглил за него. Но вопроса не было, поэтому в своем ответе я задал уточняющие вопросы:
Это вопрос или предложение? Почему вы считаете, что «https:» исчезло?
Первая часть — отсылка к технике продуктивной переписки «общаться вопросами и предложениями». Непонятно, интересовался ли посетитель, почему так сделано, или предлагал сделать
Закрепим рекомендации:
- Когда вы пишете сообщение в мессенджере или почте, перечитайте перед отправкой и проверьте, что сообщение отражает вашу мысль.
- Когда вы получили сообщение, воспринимайте его буквально, не додумывайте за автора. Если автору нужно было другое, он переспросит.
- Отвечайте на явно сформулированные вопросы. Прокомментируйте предложения: будем ли мы делать то, что предлагается, и если нет, то почему.
- Если ни вопросов, ни предложений нет, а от вас требуется реакция, и вы не знаете, что ответить, так и напишите: «Я не понимаю, в чем твой вопрос и что ты предлагаешь».
Кеширование в nginx
В прошлый раз мы рассмотрели, как в теории работает кеш и какие ошибки обычно совершают при его программировании. В этот раз я расскажу, как с помощью нескольких настроек nginx включить кеширование прямо на уровне
Я уже писал о том, как работает мой сервис генерации картинок с формулами на латехе. При первом обращении к
Иногда папку с кешем приходится удалять, если она слишком сильно разрослась. Или если я вношу правки в систему, и кеш устаревает. Посетители популярных страниц генерируют множество запросов к одинаковым формулам. В кеше их нет. Nginx направляет запросы к PHP. PHP на каждую формулу вызывает консольный скрипт латеха. Раньше у меня не было защиты от того, чтобы сервер в нагруженном состоянии хотя бы не делал одно и то же много раз. Это классическое условие гонки.
Как оказалось, приемлемое решение — включить кеш в nginx и настроить блокировку. Тогда он пропускает на бэкенд разные запросы, а одинаковые выстраивает в очередь ожидания. Результат записывает в свой внутренний временный кеш и отдает всем ожидавшим клиентам.
В блоке конфигурации http указываем папку и другие параметры зоны кеша:
fastcgi_cache_path /var/data/i.upmath.me levels=1:2 keys_zone=i_upmath:10m;
fastcgi_cache_key "$scheme$request_method$host$request_uri";Обратите внимание на ключ кеширования. Я использовал обычный адрес ресурса, потому что картинки публичны и одинаковы для всех. Если у вас закрытые ресурсы, можете попробовать добавить куки в ключ. Хотя я бы не стал так делать: велик риск ошибки и утечки чужих приватных данных через кеш.
Далее в нужном location подключаем зону:
fastcgi_cache i_upmath;
fastcgi_cache_valid 200 10m;
fastcgi_cache_methods GET HEAD;
fastcgi_cache_lock on;
fastcgi_cache_lock_age 9s;
fastcgi_cache_lock_timeout 9s;Помимо кеширования здесь включена блокировка для предотвращения race condition. Длительность блокировки и ожидания я выбрал 9 секунд, потому что таймаут запуска латеха в моей системе 8 секунд. Вы можете подобрать другое значение.
На моем сервере ограниченное количество процессов
fastcgi_buffers 8 16k;
fastcgi_buffer_size 32k;
fastcgi_connect_timeout 90;
fastcgi_send_timeout 90;Технически правильное решение в моей ситуации — прогревать новый кеш, пока система работает со старым. А именно, брать часть текущего потока запросов формул, генерировать для них новые картинки и складывать в новую папку. Когда популярные формулы окажутся в новом кеше, переключать папки.
С прогревом нового кеша пользователи не заметят подмены, и сервер будет работать в комфортном режиме. Но систему прогрева нужно еще программировать. А решение с nginx внедряется простой правкой конфига. Конечно, картинки с формулами у некоторых пользователей в момент очистки кеша перестают открываться. Но для
WSL: Линуксовая подсистема в Windows
Полноценная
В этот момент разработчики начинают использовать виртуальные машины, локальные или удаленные. Вместе с ними появляются проблемы синхронизации файлов в крупных проектах. Для продуктивной работы PhpStorm индексирует файлы проекта и наблюдает за их изменениями. Когда файлы редактируются на одной операционной системе, а исполняются и управляются из гита на другой, неизбежны задержки синхронизации или тормоза индексирования. Еще и composer
Неискушенный читатель может спросить, зачем вообще разрабатывать на Windows. Причины могут быть разные. Например, корпоративная политика. Админам проще управлять кучей компьютеров с Windows.
Так или иначе, проблема удобной настройки окружения для
Несколько лет после выхода линуксовая подсистема была в состоянии беты, и пользоваться ей было невозможно. Но, начиная с Creators Update, выпущенного в апреле, ситуация изменилась, и nginx вместе с
С практической точки зрения WSL — это командная строка bash, в которой можно устанавливать любой пакет из репозитория Ubuntu 16.04 через apt install. Диски компьютера примонтированы и доступны в файловой системе через /mnt/c, /mnt/d
Ребята из Микрософта нацеливались на «интероперабельность»: из bash можно запустить не только линуксовые
Я перевел ежедневную работу на линуксовую подсистему. Обнаружил две проблемы. Первая: не работают
Еще есть особенность: не работают средства автозапуска программ. Пришлось добавить команды service start nginx в .bashrc.
И еще есть баг. Через некоторое время процесс beam начинает загружать процессор. Приходится останавливать сервис rabbitmq.
Положительные моменты: можно выкинуть MinGW, виртуальные машины и прочие попытки завести bash на Windows, и работать в полноценной линуксовой консоли. Софт в среде разработки идентичен софту на боевом сервере и обновляется одной командой apt upgrade.
Спустя три года я
Пробел в знаниях основ веб-разработки
Одноименный перевод на хабре. Первая цитата о Реакте:
Читаю огромное множество статей, где авторы пишут о разных технологиях, и поверьте, почти все в мире JavaScript пишут об одном или другом из этих фреймворков как будто это абсолютно новая и уникальная инновация. Хотя это отличные инструменты, но каждый из них создан для решения конкретной проблемы. Они основаны на схожем базисе и делают разный выбор в зависимости от задач, для которых оптимизированы.
Можно взять React для примера, потому что он так сильно продвигается в последние несколько лет…
Не поймите меня неправильно, я люблю React. Это феноменально мощный инструмент. Он делает не только возможным, но и простым создание интерфейсов, которые казались нереальными, когда я начинал
веб-разработку. Однако новички в индустрии приходят и видят всю эту шумиху вокруг React и предполагают, что это единственная истина, как следует писать на JavaScript. Сделать новоевеб-приложение? Используй React! Нестандартный шаблон для блога? React! Переделать старый сайт? Переходи на React!
У нас на работе в команде два
Вторая цитата о том, что часто использование готовых инструментов в полную силу позволяет обойтись без велосипедов:
Если все новые разработчики будут с презрением смотреть на CSS, то мы придём к тому, что 2000 строчек JavaScript будут пытаться заново реализовать
position: absolute;.
vw и %
В css есть специальные единицы длины vw и vh, равные сотой доле ширины и высоты окна. К сожалению, на них не влияют полосы прокрутки. Например, если на странице есть блок шириной 100vw, то вдобавок к вертикальной прокрутке обязательно появится горизонтальная.
На стэковерфлоу советчик утверждает, что полоса прокрутки не входит в проценты, поэтому ширина полосы прокрутки есть 100vw - 100%, и предлагает вариант
body {
width: calc(100vw - (100vw - 100%));
}И ни советчика, ни 172 проголосовавших не смутило, что в итоге вычитания получается ровно 100%.
Viewport в Edge
Здесь описывается устаревшая технология, которая была реализована только в браузерах Opera и IE. Так как их разработчики отказались от своих движков, в современных браузерах технология не поддерживается, и была удалена из стандарта. Заметку оставлю для истории.
Для нормального отображения сайтов на узких экранах мобильников верстальщик добавляет в
<meta name="viewport" content="width=device-width, initial-scale=1">Например, вот скриншот моего сайта:

Если этого не сделать, на странице всё будет слишком мелким, а при увеличении масштаба появляется неудобная горизонтальная прокрутка:

Десять лет назад, во время появления айфона, мелкие элементы и горизонтальная прокрутка были обычной практикой в мобильных браузерах. Иначе сайты разваливались. Тогда никто не заботился о посетителях с мобильников.
Для айфона в Эпле придумали
Микрософт избрал свой путь и поддерживает специальное
Каждый раз, когда вы добавляете
@viewport {
width: device-width;
}
@-ms-viewport {
width: device-width;
}Доля пользователей Edge близка к нулю, но такие люди есть :) Так почему бы парой строк кода не сделать им приятно? И к стандартному способу управления размером видимой области ваш сайт будет готов.
Как определить домен из PHP
Илья Бирман написал про баг в Эгее, когда сайт доступен по разным доменам, и RSS кешируется то с одним доменом, то с другим.
Эгея, чтобы узнать, на каком сервере она работает, смотрит, по какому адресу её открыли — больше ей это узнать неоткуда.
Проблема этого подхода в том, что в PHP (и в любом языке вообще) не существует универсального надежного способа узнать, на каком домене открыли страницу сайта.
HTTP_HOST и SERVER_NAME
Для этих целей обычно проверяют серверную переменную HTTP_HOST. Но в ней всего лишь содержимое заголовка Host из http-запроса. Этот заголовок — часть стандарта HTTP/1.1, и в HTTP/1.0 он не обязателен. Правда, без этого заголовка не заработают виртуальные хосты — разные сайты на общем сервере. Но даже в таком случае среди сайтов есть сайт по умолчанию, открывающийся при заходе напрямую по IP. Так вот, когда устаревшие клиенты (в том числе нормальные браузеры за старыми или специально настроенными прокси) открывают сайт по умолчанию, переменная HTTP_HOST будет пустой.
Есть еще одна серверная переменная — SERVER_NAME. Обычно она содержит хост, определенный в конфигурации
server_name _;Сайт будет прекрасно открываться, но при этом в SERVER_NAME окажется знак подчеркивания.
Подробности для дальнейшего чтения на стековерфлоу: HTTP_HOST vs. SERVER_NAME.
Параметр конфигурации
Если вы делаете распространяемый движок для работы на разных серверах, у вас нет гарантированного способа определить хост, по которому открыт сайт. В моем движке S2 я скопировал способ из PunBB. В нем установочный скрипт «угадывает» адрес сайта (протокол + домен + порт + подпапка) в том числе на основе HTTP_HOST, дает возможность этот адрес отредактировать и сохраняет результат в конфигурационный файл. Затем именно этот адрес используется для генерации ссылок.
Как альтернативу Илья советует настроить редиректы. Это правильно, но, опять же, не всегда выполнимо. Например, вы настроили на сервере https, но не хотите делать редирект с http на https (вы хотите поддерживать старые браузеры, но у вас нет отдельного
Когда одна и та же страница открывается по разным адресам, Гугл рекомендует в явном виде указывать
<link rel="canonical" href="https://example.com/some/url" />Именно они попадут в поисковую выдачу. Ясно, что движок не сможет сгенерировать такой тег, если не будет знать, на каком из доменов он на самом деле работает.
Кстати, давно хотел написать о том, что https — это новый www. Он вынуждает совершать дополнительные бессмысленные действия при настройке сайта вроде редиректов с www. Ради https мне пришлось сделать в S2 поддержку тега link rel="canonical".
AMP
Статья на хабре про AMP. Вообще, эта «технология» всегда казалась мне странной. Зачем подключать
Оказалось, всё гораздо хуже. Гугл при переходе из поиска показывает кешированные
HSTS Super Cookies
В хроме есть потенциальная возможность отслеживать пользователей в режиме инкогнито. Пруф оф концепт.
HTTPS и Letsencrypt
Протокол https отличается от http передачей данных в зашифрованном виде. Обычно шифрование необходимо, когда на сайте встречаются закрытые паролем страницы. Однако есть и другие причины. Мне пришлось поддерживать https на сервисе генерации картинок с формулами на латехе, чтобы их можно было встраивать в другие
Для нормальной работы сайта по https требуется сертификат. Центры сертификации выдают их за определенную плату после подтверждения владения доменом.
С появлением сервиса Letsencrypt процедура получения сертификатов существенно упростилась. Вы устанавливаете на своем сервере клиентское программное обеспечение для общения с сервером Letsencrypt. Чтобы подтвердить владение доменом, организуете папку, содержимое которой доступно в вебе:
location ^~ /.well-known/acme-challenge {
alias /var/www/letsencrypt;
}Папка почти всегда будет пустовать. На время работы клиент Letsencrypt создает в ней файлы, а сервер их читает и убеждается, что доменом владеете действительно вы. После проверки сгенерированные сертификаты записываются в специальную папку. Вам остается подключить их к
Срок действия сертификатов — 90 дней. Но это не проблема, потому что легко настроить повторную выдачу сертификатов автоматически, по крону, например, раз в два месяца.
Насколько я понял, не поддерживаются (уже поддерживаются). Но вы можете сформировать один сертификат на несколько поддоменов. Либо создавать сертификат на каждый новый поддомен.
Официальный клиент Letsencrypt у меня на Дебиане не заработал. При запуске он скачал и установил
Letsencrypt — замечательный сервис. Он решает проблему автоматической выдачи бесплатных сертификатов и позволяет без дополнительных усилий включить на сайте протокол https.
Клиент хочет копировать эксель-таблицы на сайт
★
Попробуем новый для этого блога формат советов.
Клиент хочет копировать отформатированные таблицы из Экселя в визуальный редактор на сайте, чтобы ничего не менялось. Мы разработали сайт на базе Вордпресса, и в нем это не получается, форматирование не сохраняется. Возможно ли в принципе то, что хочет клиент? Если нет, то как это красиво и обоснованно ему объяснить?
Вот тут пишут, что можно настроить визуальный редактор Вордпресса TinyMCE. Правда, в комментариях отмечают, что это зависит от версии Экселя, так что решение может быть не универсальным.
Как применить это решение в вашем конкретном случае — не знаю. Возможно, поможет плагин
Вообще я бы запрещал любое форматирование, кроме курсива и жирного текста. Если клиент просит возможность копировать фрагменты таблицы из Экселя с форматированием, надо выяснять, какую задачу клиент будет решать таким способом.
Возможный выход — договориться о разработке дополнительной функциональности по загрузке
В варианте с копированием из Экселя больше неконтролируемых звеньев, в которых
Латех в вебе
Постоянные читатели помнят, что у меня есть движок сайтов S2, и он с помощью расширения s2_latex ищет в тексте страницы формулы на латехе и заменяет их на картинки. Расширение обращается к сервису codecogs.com. Этот сервис зачастую глючит, и я уже давно сделал свой, с
Мой сервис делает из формул картинки. Вот, для примера, знакомое всем решение квадратного уравнения в SVG и PNG:
На обычных мониторах преимуществ у SVG нет. Но на ретине или при большом увеличении SVG выглядит более чем достойно. А за ретиной будущее.
В

Символы в формулах крупнее и жирнее, чем в окружающем тексте. Они в буквальном смысле выпадают из окружающего текста. Меняем гротеск на антикву, увеличиваем кегль и добавляем выравнивание по базовой линии:

Теперь буквы в формулах аккуратно располагаются на тех же линиях, что и буквы в окружающем тексте. Чтобы заработала магия с выравниванием по базовой линии, к странице нужно подключить специальный скрипт.
У
Я подготовил описание сервиса и инструкцию. Посмотреть сервис в работе можно в блоге о теоретической физике. В следующий раз я расскажу о том, как всё это работает.
Ember и трудности отладки
Разрабатываю некий сайт, на котором должно быть много яваскрипта и аякса. Посмотрел модные
Основные достоинства Эмбера по сравнению с обычным подходом (jQuery и нагромождение обработчиков
Я еще не достиг той степени просветления, когда достигается экономия в 146%, и еще натыкаюсь на разные трудности. Вот забавный пример. Делал одну страницу по аналогии с уже готовой.
Assertion failed: The value that #each loops over must be an Array. You passed ArrayОбычно сообщения Эмбера помогают понять, что не в порядке. Но не в этот раз. Я и сам знаю, что в цикл нужно передать массив, и что я передал массив. Разобрался с проблемой, только когда посмотрел, какие данные присылает сервер. Как оказалось, я забыл обновить серверную часть и сделать сериализацию массива, и при сохранении в БД insert_or_update_assoc_array(), код которой приведен ниже, приводила массив к строке 'Array' и записывала ее в БД. Таким образом, под фразой «You passed Array» имеется в виду «вы передали строку 'Array', а не массив».
public function insert_or_update_assoc_array (array $params, $table)
{
$values = array();
foreach ($params as $name => $value)
$values[] = ((string) $name) . '=' . ($value === null ? 'NULL' : (is_numeric($value) ? (string) $value : '\'' . $this->escape((string) $value) . '\''));
$values = implode(', ', $values);
$sql = 'INSERT INTO '.$table.' SET '.$values.' ON DUPLICATE KEY UPDATE '.$values;
$this->query($sql);
}
К недостаткам Эмбера относится его размер. Фреймворк в несколько раз тяжелее jQuery. Впрочем, умные ребята давно настроили автоматическое сжатие, объединение и архивирование стилей и скриптов при развертывании сайта из систем контроля версий. В таком случае подключение Эмбера эквивалентно добавлению
Еще я так и не понял, как обстоят дела с кроссбраузерностью. В документации об этом нет ни слова, и поиск по интернету ничего толкового не дает. У меня сайт не заработал в IE8, и я так и не понял: это так и должно быть, или я
Разучились делать сайты
Отключился интернет. Сижу с телефона. Вспоминаю модемную скорость 64 килобита в секунду.
Редкий сайт открывается за приемлемое время. (Мой, конечно, открывается.)
Эх, разучились люди делать сайты.
Переносы в вебе и выключка по формату
Позавчера я написал о том, что в браузерах постепенно начала появляться поддержка автоматических переносов. Немного подумал и нашел способ, как можно уже сейчас использовать на сайтах выключку по формату («выравнивание по ширине»), если браузер поддерживает переносы.
Читайте на Хабре: «Переносы в вебе и выключка по формату».
Переносы в вебе
В черновике CSS 3 для переносов строк есть свойство hyphens. Оказывается, Firefox 8 (и последние версии Safari) уже умеет автоматически переносить русские слова.
Вообще непонятно, почему с этим тянули так долго. Для технической реализации нужны лишь словари. (Браузеры уже несколько лет проверяют правописание, для чего тоже нужны словари.)
Похоже, скоро в вебе уже можно будет растягивать текст по ширине (скриншот из FF):

Градиент на сайте Яндекса
Среди прочих недавних изменений на Яндексе упоминается градиент на желтой
Я понял, что происходит, когда открыл сайт Яндекса в другом браузере.
.b-head-search_grad_yes {
background-image:-webkit-gradient(linear,0 0,0 100%,from(#fff09c),to(#f4be02));
background-image:-moz-linear-gradient(top,#fff09c,#f4be02);
background-image:linear-gradient(top,#fff09c,#f4be02)
}Непонятно, кто помешал технологам Яндекса добавить еще одну инструкцию -o-linear-gradient для второго по популярности браузера в рунете.
Восстановление текстов в новой версии S2
В новой версии движка S2, которую я выпустил вчера, появилось очень важное нововведение. Теперь он умеет восстанавливать несохраненные тексты после непредвиденных ситуаций вроде зависаний или падений браузера, случайного закрытия окна и т. д.
Интерфейс простой. При следующем входе в админку выводится вот такое сообщение:
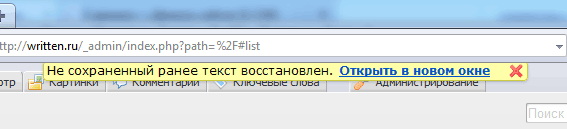
Восстановленный текст из нового окна можно затем скопировать куда угодно.
Реализация тоже крайне простая. Каждые 5 секунд содержимое редактора отправляется в
С помощью этого способа (в отличие от автосохранения) мы оставляем пользователю контроль над тем, когда сохранять редактируемый текст, но избавляемся от проблемы утери несохраненного текста при компьютерных сбоях или непродуманных действиях пользователя.
browser.js
Случайно заглянул в файл Оперы browser.js. В нем собраны в том числе исправления глюков множества сайтов в Опере. Вот, например:
else if(hostname.indexOf('.google.')>-1&&href.indexOf('/reader/view')>-1){
// PATCH-32, Google Reader wraps long feed titles
addCssToDocument(".scroll-tree .name { display: block;}");
if(self==top)
postError.call(opera, 'Opera has modified the JavaScript on '+
hostname+
' (Google Reader wraps long feed titles). See browser.js for details');
}
Там есть не только Гугл, но и Микрософт, Фейсбук, Твиттер. Если бы я был разработчиком
Left outer join
Недавно писал один
CSS и переменные
Вот тут не понимают, зачем в CSS нужны переменные.
И последняя фантазия разработчиков уж точно кажется немного безумной — введение
css-переменных. Неужели CSS превратится в полноценный язык программирования и управления html элементами?…
Идея все же не проработана. Зачем определять для цвета переменную, если его можно просто указать?
Написать такое мог только человек, максимум оформивший с помощью CSS несколько сайтов. Странно только, что в обсуждении не указали самый убедительный аргумент в пользу переменных: разработка системы плагинов, когда набор цветов (фон, цвет текста, рамки, сообщения об ошибках и т. д.) указывается в основном CSS (возможно, в стиле оформления) и потом используется в плагинах как угодно.
Офлайновая версия сайта
Если бы существовали компиляторы CHM под linux, всё было бы вообще здорово. Однако таких компиляторов не существовало. Я хотел было сам написать такой компилятор, но из этого так ничего и не получилось.
Потом я подумал о других форматах и вспомнил о PDF. Как оказалось, с PDF в вебе не всё так безнадежно, как с CHM. У меня даже получилось сделать
Однако у такого решения есть ряд недостатков.
Я думал над этими недостатками и пришел к гениальному выводу:
Преимущества такого подхода очевидны — пользователь сам может управлять отображением на экране и на бумаге. К печатной версии можно применить отдельные стили и показать, например, URL'ы ссылок. А еще пользователь сможет открыть такой документ в Ворде и распечатать своим любимым шрифтом.
Впрочем, вариант с PDF тоже можно спасти.
Adobe Air
Бывает, у нас в институте проводят лекции и презентации известные люди и компании, специализирующиеся в разработке программного обеспечения. В 2005 году я был на лекции Касперского. В прошлом году сначала Google, а потом и Microsoft провели свои презентации. Неделю назад читал лекцию Ричард Столлман (на эту лекцию я, к сожалению, не смог попасть). И вот в пятницу Adobe провела презентацию своих двух продуктов: Flex и Air.
Я не буду подробно останавливаться ни на презентации, ни на качестве ее проведения. Достаточно упомянуть, что они попытались сделать
Сначала нам рассказывали про Flash и Flex. Потом речь дошла до Adobe Air. Оказывается, это такая примочка, которая превращает
Практически единственный произнесенный на презентации аргумент, подтверждающий полезность Adobe Air, состоит в том, что не нужно разрабатывать два приложения, для веба и для десктопа, достаточно разработать одно. Однако ясно, что HTML и JavaScript изначально не предназначались для построения интерфейсов, поэтому создавать в них интерфейсы непросто, да и по возможностям они будут уступать традиционным предложениям (об этом я уже писал в статье про Ajax).
Я потратил заметное время на разработку административного интерфейса движка SiteX (в нем используется Ajax). За это время я бы разработал на Delphi принципиально другой интерфейс, не ограниченный рамками HTML и JavaScript, разобрался бы, как из программы на Delphi делать Get- и
И последнее соображение. Я глубоко убежден в том, что хорошему программисту всё равно, на каком языке писать программы. И если есть Delphi, зачем еще нужен Adobe Air?
Защита от спама
О, сегодня пришел первый спаммерский комментарий после внедрения новой системы защиты. Один посторонний комментарий за полгода — очень неплохо :) Правда, в данном случае, как следует из логов (прогрузились CSS, JS, картинки), он был сделан не тупым спаммерским ботом, а полноценным браузером. Новая хитроумная система, обходящая любую защиту? На этот раз, к счастью, всё в порядке. Путь от запроса в Гугле к странице с комментариями мог проделать только человек.
Добавлено: появился еще один комментарий. Почерк такой же. Удалил оба. На этот раз пришли по запросу с Яндекса.
О спаме в гостевых и комментариях
Месяца два назад в мою гостевую повалил спам. Посмотрел логи сервера. Разумеется,
Тогда я поленился всё это делать и изменил URL гостевой, а так же имена полей в форме ввода сообщения. Как оказалось, хорошо, что я поленился. Пару дней назад ко мне на сайт попали вот по такому запросу из Рамблера: гостевая. Интересно, они просматривали эти 2700 сайтов вручную, или это тоже был скрипт? И после в гостевой опять началось безобразие. Главная особенность — перед отправкой
Надо подумать о методе, позволяющем фильтровать спам. Способ CAPTCHA, в котором пользователю предлагается прочесть текст на картинке и написать его в специально отведенное поле ввода, конечно, хорош. Но слишком уж он неудобен для пользователя. Я его просто ненавижу.
Хорошо еще, что спамеры не добрались до комментариев к статьям и к записям в блоге. Тогда точно надо будет придумывать
О спаме
Похоже, методы борьбы со спамом, использующие javascript, действительно хороши (подробности для интересующихся). На ящик, красующийся внизу каждой страницы, не пришло ни одного лишнего письма.
Но, видимо, спамеры не дремлют. Они пытаются отсылать письма на несуществующие адреса, например, на sale, buh, personal перед знаком @ и доменом. Пришлось отключить сбор почты на такие адреса.
Мозг крысы оценивает сайты
Меня весьма заинтересовал проект Cybernetic Analytic System. По заявлениям авторов, они построили систему оценивания сайтов, «изюминкой» которой является культура клеток крысиного мозга, подключенная к компьютеру. Цитата:
Но главный промежуточный результатAI-составляющей Кибераналитика — нейропространственнаяцифро-аналоговая матрица, которая затем анализируется нейронной составляющей Кибераналитика. Эта часть Кибераналитика управляется крысиными клетками мозга. Компьютер используется лишь для анализа нервных сигналов, поступающих от клеток крысиного мозга.
Разумеется, я стал проверять разные сайты и смотреть, что выдает система. Честно говоря, работы
Оценка сайтов
Признаки наглой оптимизации при помощи невоздержанного примения заголовков.
Невоздержанное «примение» заголовков! Какой ужас! И это она говорит в ответ на вполне корректное, и, даже более того, рекомендуемое стандартом применение тегов H1, H2 и т.д.
Однако, если уже сейчас подобная система действительно существует и функционирует, кто знает, к чему приведет развитие этих технологий в обозримом будущем…
Добавлено 16.05.2007: Вот, кстати, что говорит эта система сейчас:
Верстка выполнена на высоком профессиональном уровне. Качество технической реализации практически безупречно.
Неплохо обеспечено функциональное предназначение страницы. Есть некоторые спорные моменты в реализации навигации.
Достаточно удачный дизайн и цветовое оформление страницы. Возможно, недостаточно тщательно прорисованиы графические элементы.
Отличная работоспособность во многих современных и старых браузерах. Грамотный баланс изящества и совместимости.
Про графические элементы он прав —