Cистема рекомендаций на сайте
Сделал для своего сайта систему рекомендаций. После каждой заметки отображаются аккуратно сверстанные ссылки на похожие материалы. Вот несколько скриншотов, показывающих, как это выглядит.
Пример 1 — антикоррупционный митинг:

Пример 2 — где учиться, на физтехе или физфаке:
Пример 3 — сворачивание кешбека в Бинбанке:
Систему рекомендаций в таком виде сделал Илья Бирман в Эгее — своем движке блогов. В его случае рекомендации к постам формируются на основе тегов. Тогда у меня появилась идея, как можно подбирать рекомендации на основе анализа текстов, без необходимости расставлять теги. Но одно дело — идея, и совсем другое — работающий продукт.
Подбор рекомендаций
Чтобы воплотить идею в жизнь, мне пришлось сделать много подготовительной работы.
Я подключил к моему движку сайтов S2 поисковый движок Rose. s2/search). Но Илья убедил меня, что библиотеке для поиска, как и любому продукту, нужно нормальное имя, и даже предложил несколько вариантов. Название «Ropsen», содержащее первые буквы из Roman Parpalak Search Engine,
Вместе с именем в Розе многое поменялось внутри. Я привел в порядок код, чтобы он следовал правилам хорошего тона для библиотек на PHP: с интерфейсами, инверсией зависимостей и прочими вещами, скрытыми за аббревиатурой SOLID. Кроме того, я сделал реализацию хранилища поискового индекса в MySQL (предыдущая реализация была просто в файле).
Поиск в S2 продолжал работать на старой кодовой базе. Мне казалось, что потребуется много времени, чтобы удалить из
Почему я вообще в заметке о рекомендациях пишу уже четвертый абзац не о рекомендациях, а о поиске? Потому что рекомендации к некоторой заметке на основе ее текста — это, грубо говоря, результаты поиска по словам из этой заметки. Мне удалось написать
Оформление рекомендаций
Чтобы выводить рекомендуемые заметки не просто списком, мне пришлось доработать поисковый движок Rose, чтобы в нем сохранялись предложения из проиндексированных заметок и информация о картинках.
Мне очень понравилось, как выглядят рекомендации у Ильи, и я решил сделать так же. Кроме того, он в своем докладе об автоматическом дизайне рассказал, каким образом работает автоматическая верстка рекомендаций в Эгее. Он подготовил список хорошо сверстанных вариантов и перевел их в некоторый декларативный конфиг с описанием критериев соответствия для каждого элемента верстки (вроде размера и пропорций картинок, длины заголовка и прочего). Дальше для набора рекомендуемых заметок подбирается наиболее подходящий вариант верстки. Обязательно посмотрите видео по ссылке о том, как это всё придумано и работает.
После повторного просмотра видео доклада, которое можно считать подробным и понятным техзаданием, я понял, что не смогу придумать
Тем не менее, я сделал свой декларативный язык. Описал несколько очевидных вариантов верстки, например для пяти рекомендаций: одна крупная рекомендация слева и четыре поменьше справа.
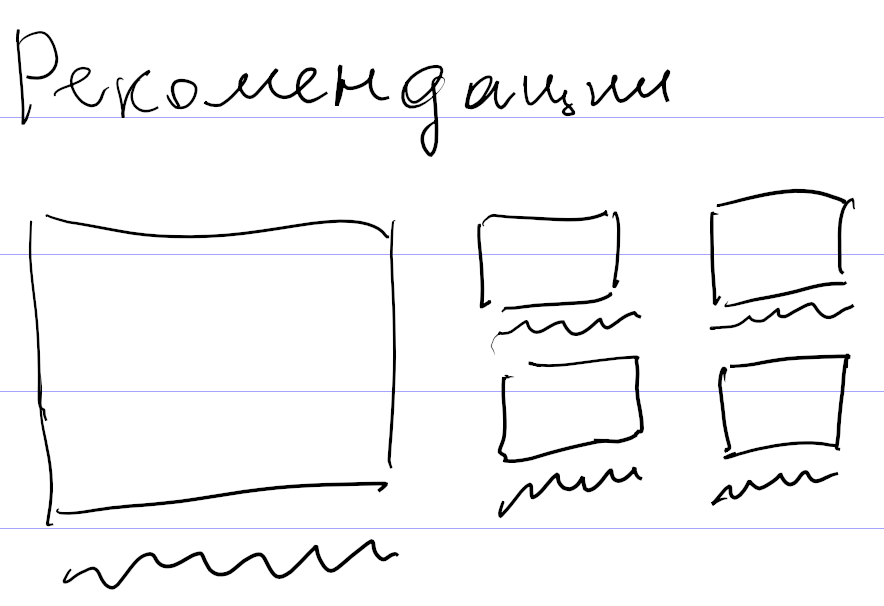
Затем стал смотреть, как имеющиеся рекомендации ко всем подряд заметкам раскладываются по этим вариантам верстки. Выбрал критерий успеха: заметки с картинками не должны выводиться без превьюшек картинок. Если этот критерий не выполнялся, значит, для таких рекомендаций не было подходящего варианта верстки. Я смотрел на них и прикидывал, как надо вывести заметки, чтобы использовать все возможные картинки. Причем делал это не в графическом редакторе, а сразу описывал новый вариант на своем декларативном языке, и он применялся к рекомендациям.
В результате таким способом, никуда не подглядывая, я накопипастил 113 вариантов верстки. Ближе к концу я стал понимать, что это
В процессе мне пришлось изобрести некоторые неочевидные приемы. Например, после определения варианта верстки я сортирую рекомендации по убыванию высоты картинок, а если высота одинакова или картинок вообще нет — по убыванию длины текста. Это нужно, чтобы дыры в верстке появлялись ближе к правому краю, который и так рваный, а не к левому. С дырами получалось забавно: я начал было подбирать длины текста так, чтобы он максимально заполнял дыры. Но рекомендации в некоторых пределах резиновые, а при изменении ширины страницы такие объекты как картинка и текст ведут себя
Еще одно изобретение — отрицательная максимальная длина текста. Она появилась при попытке собрать из картинки и текста блок примерно одинаковой высоты. Скажем, на
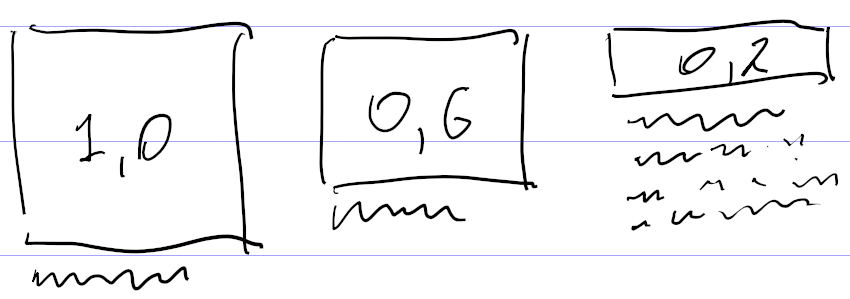
Чтобы не плодить разные варианты одной и той же верстки с таким отличием, я придумал характеризовать текст не только минимальной и максимальной длиной, но и дополнительным коэффициентом, на который умножается «нехватка» высоты картинки для определения дополнительной длины текста. А если картинка с высотой 1,0 тоже подходит, то у картинки с высотой 0,6 за счет добавки обязательно появится текст.
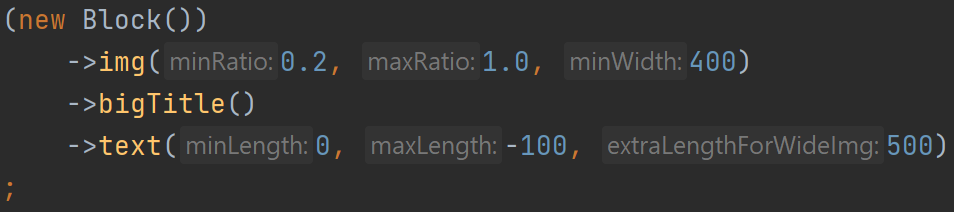
Сначала я хотел сделать дополнительный параметр для отсчета нехватки высоты от 0,6, а не от 1,0. Но потом понял, что того же можно добиться отрицательной длиной текста.
Ограничения рекомендаций и планы на будущее
У Ильи кроме рекомендаций есть еще и перебивки — оформленные таким же образом ссылки в списках записей. Я не стал их делать. В моем понимании рекомендации решают задачу направить посетителя почитать другие записи. Но в списках и так достаточно записей для чтения. Да и технически подобрать ссылки к нескольким записям на одной странице тяжелее, чем к одной записи. Нужно исключать повторы, чтобы одинаковые блоки не повторялись на этой странице.
Сейчас, если в блоке рекомендаций надо вывести текст, я беру
Зарисовка для объяснения понятия формата
Нашел черновик статьи о понятии формата и вебе, которую я так и не написал и вместо которой снял видео из серии «в кресле препода». В черновик я успел написать только одну зарисовку для иллюстрации понятия формата. В видео зарисовка не вошла, вместо нее я сослался на известный ролик о работе техподдержки. Решил опубликовать черновик, может
Многие люди, даже профессионально занимающиеся разработкой сайтов, имеют смутные представления о понятии формата. Это понятие играет трудно уловимую, но важную роль в проектировании и разработке сайтов. Чем больше будущий сайт соответствует формату, тем быстрее пойдет разработка и тем проще будет посетителям.
Чтобы пояснить, что я подразумеваю под форматом, рассмотрим для примера газеты и книги. И то и другое — печатная продукция. На газетах распространяется небольшая порция ежедневной информации. Их после прочтения выбрасывают. Поэтому газеты печатают на дешевой тонкой бумаге. Книги объемнее, используются и хранятся долго. Их печатают на хорошей плотной бумаге и переплетают.
Можно представить, что будет с романом, напечатанным в формате газеты, а не формате книги. А вот более яркий пример. Представьте, что вы работаете в типографии и к вам приходит клиент.
— Я хочу напечатать свою поэму.
— Какой у вас тираж?
— Штук сто,
— Большая поэма? Сколько страниц?
— 100 страниц в Ворде. Но я не хочу, чтобы это была обычная книга. Я хочу напечатать на рулоне бумаги.
— Что? — вырывается у вас с плохо скрываемым удивлением.
— Ну на таком рулоне, типа как обои, только поменьше, — размахивает руками клиент.
— А чем вас книга не устраивает?
— Книга? Это вчерашний день. Рулон удобнее.
— Чем же он удобнее?
— Как чем? Страницы в книге нужно перелистывать. Это неудобно. На время перелистывания отрываешься от чтения. Ну и если книга закроется, трудно найти место, где читал, если не запомнить страницу.
— И что? А причем тут рулон?
— Ну как причем? Если напечатать на рулоне, то в процессе чтения его легко перематывать. Не нужно перескакивать с одной страницы на другую. И рулон можно спокойно отложить, он не закроется.
— Я вообще первый раз такое слышу. Все печатают и читают книги. Их удобно носить и держать на полке. И недостатки не такие уж и большие. Есть же закладки, оглавление. И перевернуть страницу ничего не стоит.
— Если все
— Извините, у нас нет такого оборудования, — мягко посылаете клиента.
Разговор в таком стиле вряд ли возможен о привычных предметах окружающего мира, но постоянно встречается при обсуждении компьютерных интерфейсов. Я задумался, почему так происходит, когда прочитал на хабрахабре статью о критике современных
Как нормально сверстать хотя бы такой блокнотик с закладками на CSS/HTML без извращений и большого количества JS кода вовсе не ради динамики, а прямо для самой отрисовки и позиционирования?
И из моего ответа:
Есть понятие формата, которое вы себе, судя по уже второму посту, плохо представляете. Нужно думать не о переносе конкретной реализации блокнотика из операционной системы в веб, а о решении той же задачи, которую решал блокнотик.
Очевидно, этот блокнотик был придуман, чтобы разместить в одном окне ограниченного размера как можно больше элементов управления. Даже если оставить в стороне уродливость внешнего вида, такое решение со вкладками не является очень хорошим примером интерфейса, так как пользователь не знает (или не помнит, ведь окном настройки не пользуются постоянно) плотность заполнения каждой вкладки и не имеет представления о том, сколько еще параметров можно изменить.
Проблема нехватки места в вебе прекрасно решается прокруткой. Поэтому, чтобы решить ту же задачу, нужно поместить друг под другом содержимое каждой вкладки, предваренное крупными заголовками. У такого метода целая куча достоинств. К прокрутке привыкли все. На больших экранах пользователь увидит сразу всю форму. Таким образом, на HTML/CSS блокнотика нет, но задача, которую он выполнял, решается.
При проектировании интерфейсов не нужно забывать о формате.
Еще в черновике было написано graceful degradation и progressive enhancement. Скорее всего, я хотел сказать, что начинать разработку надо с чистого HTML, а затем добавлять оформление в CSS и поведение в JS (progressive enhancement). А не делать наоборот — сначала разработать
Кстати, посмотрите само видео о понятии формата, если еще не посмотрели или уже забыли, о чем оно:
Мастер костылей, или сущности в DOMDocument
Я тут решил потратить некоторое время на собственные проекты. Сейчас перерабатываю движок для поиска Rose. На нем работает поиск на этом сайте, также его использует Илья Бирман в Эгее.
Для извлечения текста из
Как оказалось, DOM API не поддерживает HTML5. Это выливается в практическую проблему с непоследовательной обработкой сущностей HTML. Например, если в исходнике написать & ★, при получении текстового содержимого из & ★. Видим, что первая сущность из HTML предыдущих версий распознается и раскодируется, а вторая из HTML5 — нет. Такие ошибки приведут к искажениям при выводе сниппетов.
Моя первая идея — прогнать текстовое содержимое через html_entity_decode($a, ENT_HTML5);. Действительно, что не доделал встроенный парсер, доделает эта функция. Но проблема в том, что раскодирование неидемпотентно. Если на вход подать ★, то после DOM API мы получим ★. И на этапе повторного раскодирования мы не будем знать, нужно ли раскодировать ★ еще раз, или нет.
Поиск проблемы в гугле разумного решения не выявил. В классе DOMDocument есть
Для начала нужно все вхождения амперсанда заменить на его сущность:
$text = str_replace('&', '&', $text);После этого DOM API раскодирует копии только одой сущности — этого самого амперсанда. При рекурсивном обходе в текстовом содержимом узлов html_entity_decode($a, ENT_HTML5);.
Уже который раз убеждаюсь, что искусство программиста во многом заключается в умении подобрать нужный костыль. Так и живем.
Отладка запросов к FastCGI из консоли
Обычно протокол FastCGI применяется для общения между
Однако как быть, если у вас есть собственный сервис, работающий по протоколу FastCGI (скажем, простая асинхронная очередь через
Можно было бы настроить в nginx отдельный location, подключить к нему отлаживаемый сервис и отправлять
Предположим, у вас есть скрипт, который забирает входные данные из $_POST['formula'] и $_POST['extension']. Тогда вызвать этот скрипт с данными formula=12345 и extension=svg можно вот так:
user@tau:~$ echo "formula=12345&extension=svg" | sudo -uwww-data \
> CONTENT_TYPE='application/x-www-form-urlencoded' CONTENT_LENGTH=28 \
> SCRIPT_FILENAME=/var/www/.../.../cache_processor.php \
> REQUEST_METHOD=POST cgi-fcgi -bind -connect /var/run/php_fpm.sockВ консоли мы увидим ответ, например, такой:
PHP message: PHP Warning: file_get_contents(...): failed to open stream: No such file or directory in ... on line 88Content-type: text/html; charset=UTF-8
В этом методе используется утилита
Про войну
Скоро уже будет год, как идет война в Украине (я называю вещи своими именами, как и Путин). Я хотел написать о войне раньше. Текст мне не понравился, я не стал публиковать его. Но и писать о
Решил сформулировать и записать свои мысли и ощущения. Не потому, что они представляют для
Стремительное начало войны было для меня совсем неожиданным. Первые дни тяжело было психологически. Невозможно было представить, что твоя страна нападает на ближайшего соседа и развязывает полномасштабную войну. Логика подсказывает, что ты должен быть на стороне жертвы и оправдывать отпор агрессору. Но отпор в этом случае — убийство таких же во многом невиновных людей. И становилось еще хуже от ощущения, что ни на что повлиять не можешь.
Немного помогали проявления солидарности с Украиной в повседневной жизни. Вот, например, 26 февраля украинский флаг на гирлянде с управляемой подсветкой:

Больше я такой подсветки в этом окне не видел. Надеюсь, его не разбили. А вот еще идеологическая борьба на лестничной площадке, где неравнодушный житель оставлял надписи, а его противник не ленился искать краску и их замазывать:


Из рациональных мыслей в начале войны у меня была одна, которой можно поделиться. Нападение Путина на Украину можно сравнить с нападением Сталина на Польшу в 1939 году. Он тоже проводил «военную операцию» в Польше после подписания пакта Молотова — Риббентропа и секретного протокола к нему (подлинность этих документов подтверждена МИДом в 2019 году). Но Сталин смог оказаться среди победителей во второй мировой войне и участвовать в ялтинском разделе мира только
Выходить на протесты я не стал. Сейчас любой протест автоматом означает задержание. И польза от протестов может быть только в расколе элит, что возможно при численности митингов от миллионов или хотя бы нескольких сот тысяч людей. Сегодня это непредставимые числа. 10 лет назад была совершенно другая атмосфера. Как очевидцу событий на Болотной мне было ясно, что Путин самостоятельно из Кремля не уйдет. А уже 8 лет назад, когда происходили события в Крыму, «очнувшимся» людям с вопросом «а что можно сделать?» оставался только один ответ — «валить». Хотя тогда всё еще можно было выйти на марш против войны, но его численность была на порядок меньше необходимой.
В новостях сообщали о задержаниях людей даже с пустым листом бумаги. Известный анекдот советских времен про мужика, разбрасывающего пустые листовки, стал реальностью. Кроме того, стали реальностью даже лозунги из оруэлловской антиутопии «1984»: «война — это мир, свобода — это рабство, незнание — сила».
Кстати, Марш мира и Марш правды — это ответ на вопрос о том, где я был 8 лет назад. И у меня для вас есть встречный вопрос — а где вы были 11 лет назад, когда Путин в нарушение конституции возвращался в кресло президента, чтобы оставить более заметный след в учебнике истории? Если бы он не пошел на выборы в 2012 году, его бы все вспоминали как хорошего президента. А как его будут вспоминать теперь?
Еще в черновике было
Прокси-сервер через ssh
Полезная вещь в современных условиях —
ssh -D 1337 -q -C -N example.comРазумеется, вместо example.com нужно подставить ваш хост. После запуска вы можете использовать localhost и порт 1337 как параметры SOCKS5
Если у вас windows, можете взять консоль WSL, установить MinGW или поискать аналогичную функциональность в PuTTY на вкладке Connection/SSH/Tunnels.
Как додуматься до решения олимпиадной задачи — 2
В прошлый раз я рассказывал о ходе своих мыслей при решении олимпиадной задачи. Может быть такие рассказы помогут
Условие задачи
Есть 3 различных натуральных числа $$x$$, $$y$$, $$z$$. Эти числа оказались подобраны так, что выражение
$$A={xy+yz+zx\over x+y+x}$$
тоже натуральное. Каким числом оно может быть? Иными словами, каково пересечение множества значений этой функции трех натуральных переменных и множества натуральных чисел?
Поиск решения
Идея №1: вынести в числителе за скобки $$xyz$$. Получается
$$A={\left({1\over x}+{1\over y}+{1\over z}\right)xyz\over x+y+x}.$$
Из этого я заметил, что при замене величин $$x$$, $$y$$ и $$z$$ на обратные $$1/x$$, $$1/y$$ и $$1/z$$ выражение «переворачивается», то есть $$A$$ меняется на $$1/A$$. Дальше у идеи не было очевидного развития, я решил попробовать другие идеи.
Идея №2: масштабирование. Видно, что если выполнить замену $$x$$, $$y$$ и $$z$$ на $$kx$$, $$ky$$ и $$kz$$, то числитель $$A$$ вырастет в $$k^2$$ раз, а знаменатель в $$k$$ раз, то есть $$A$$ меняется на $$kA$$. Как это можно применить? Пусть мы выбрали натуральные числа равными 1, 2 и 3. Тогда
$$A={2+6+3\over 1+2+3}={11\over 6}.$$
Чтобы из этого набора получить целое $$A=11$$, можно взять не 1, 2 и 3, а 6, 12 и 18.
Однако я не стал развивать дальше эту идею
Идея №3: перебор вариантов.
Чтобы прочувствовать задачу, часто бывает полезно рассмотреть некоторые частные случаи. В задачах вроде этой подобрать $$x$$, $$y$$ и $$z$$, чтобы выражение действительно было целым. В геометрических задачах бывает полезно нарисовать на черновике хороший чертеж, чтобы заметить закономерности вроде расположения точек на одной прямой или окружности.
Для перебора будем фиксировать значения $$x$$, $$y$$ и изменять $$z$$. Пусть $$x=y=1$$ (я проделал эту лишнюю работу, потому что невнимательно прочитал условие).
$$A={1+z+z\over 1+1+z}={1+2z\over 2+z}={4+2z-3\over 2+z}=2-{3\over 2+z}.$$
Ясно, что $$A=1$$ при $$z=1$$, а значение $$A=2$$ ни при каком $$z$$ не будет достигнуто.
Пусть $$x=1, y=2$$. Тогда
$$A={2+2z+z\over 1+2+z}={2+3z\over 3+z}.$$
Если $$z$$ нечетное, то числитель нечетный, знаменатель четный, $$A$$ не будет целым. Если $$z$$ четное, то числитель четный, знаменатель нечетный. Здесь я сделал еще одну ошибку, подумав, что четное число не может делиться на нечетное, и вообще исключил из рассмотрения варианты с $$x$$ и $$y$$ разной четности.
Пусть $$x=1, y=3$$. Тогда
$$A={3+3z+z\over 1+3+z}={3+4z\over 4+z}.$$
Здесь исключаем случай четного $$z$$, так как нечетный знаменатель не будет делиться на четный числитель. Попробуем подставить разные нечетные $$z$$. Получим:
$$ z=1\implies A={7/5}\\ z=3\implies A={12/7}\\ z=5\implies A={23/9}\\ z=7\implies A={31/11}\\ z=9\implies A={39/13}=3\\ z=11\implies A={47/15}\\ $$
Далее, сколько бы мы ни увеличивали $$z$$, до значения 4 мы не дойдем, так как 4 достигается только в пределе $$z\to\infty$$. Таким образом, при $$x=1, y=3$$ единственное целое $$A$$ дает $$z=9$$.
Пусть $$x=1, y=5$$. Тогда
$$A={5+5z+z\over 1+5+z}={5+6z\over 6+z}.$$
Перебор $$z$$ слишком долгий, и мы понимаем, что возможных значений $$A$$ не так уж много. Поэтому решим уравнение относительно $$z$$:
$$5+6z=A(6+z)\iff(6-A)z=6A-5\implies z={6A-5\over 6-A}.$$
Отсюда видно, что $$A$$ не может быть четным. 1 и 3 не подходят, $$A=5$$ дает $$z=25$$, других значений для проверки нет.
Мы видим, что значения переменных (1, 3, 9) и (1, 5, 25) дают целые значения $$A$$. Кажется, это и есть нужная закономерность.
Решение
Подставим значения $$x=1, y=n, z=n^2$$. Тогда
$$A={n+n^3+n^2\over 1+n+n^2}=n\,{1+n^2+n\over 1+n+n^2}=n.$$
Таким образом, мы можем в качестве значения выражения получить любое натуральное число, не равное 1. То, что 1 получить нельзя, посмотрите у Савватеева или докажите самостоятельно.
Обсуждение ошибок
После подстановки $$x=1, y=n, z=n^2$$ моя ошибка с четностью стала очевидной. Сначала мне вообще не хотелось писать об ошибках. Признаваться в них не очень приятно. Но с другой стороны, благодаря ошибкам на этапе поиска решения я довольно быстро нашел правильное решение. Могло бы оказаться так, что я углубился в разработку
Чтобы минимизировать ошибки на олимпиадах, важно не переписывать решение с черновика на чистовик, а заново решить задачу на чистовике, обращаясь к черновику только для сравнения вычислений. Об этом и других советах я уже писал в руководстве олимпиадника.
Необычный сон и шутка про банки
Сегодня мне приснился странный сон.
В моем сне Иван Голунов ведет новости или
Дальше Голунов говорит Рыжкову: «А помните, как та шутка — „банк — он же не
Термины
Виртуальные частицы часто используют в популярных объяснениях квантовых эффектов. Например, говорят, что физический вакуум — нулевые колебания квантовых полей — можно представить через рождение и уничтожение пар виртуальных частиц и античастиц. Они могут родиться на короткое время и почти сразу же аннигилировать, причем степень нарушения закона сохранения энергии, необходимая для рождения таких частиц, связана со временем их жизни через соотношения неопределенностей Гейзенберга. Однако если приложить достаточную энергию, виртуальные частицы могут стать реальными. Так объясняется излучение Хокинга, когда вблизи горизонта событий одна виртуальная частица получает достаточную энергию и покидает окрестность черной дыры, а другая поглощается.
Таким образом, фраза «банк — он же не
Итак, шутка из сна могла быть про диалог двух физиков:
— Не могу понять, как банк может выдать кредитов больше, чем у него есть денег вкладчиков.
— Банк — он же не
Можете воспользоваться, если окажетесь в компании физиков, обсуждающих экономику :)
Самая большая загадка: каким образом это всё оказалось в моем сне? Я иногда про себя отмечаю ошибку с употреблением слова «функционал» вместо «функциональность» в речи других, поэтому эта часть как раз не удивительна. Почему во сне были Голунов и Рыжков — не понимаю, я давно о них ничего не слышал. Термины
Савватеев и Шпилькин разбирают статистику с выборов
Сергей Шпилькин — это тот самый физик, который обрабатывает математическими методами данные с выборов. Если вы до сих пор не читали и не разбирались в его результатах, посмотрите, как они с Савватеевым обсуждают графики, гипотезы и вообще применимость к выборам математических методов как таковых.
Пару раз они забылись и произнесли понятные только специалистам термины вроде «минимального детерминанта матрицы ковариации», но на восприятии основного посыла это не сказалось.
Переезд сайта на parpalak.com
На выходных перевел этот сайт с домена written.ru на parpalak.com. Я затеял этот переезд не только
Домен второго уровня я решил зарегистрировать в 2006 году. Рассматривал разные варианты. Домен parpalak.ru оказался занятым. По данным whois его зарегистрировал некий Орест Парпалак. Никакого сайта на этом домене не было, домен использовался для почты. Домен roma.ru тоже оказался занятым. Сейчас по нему открывается сообщение, что домен не продается. А вот раньше там была даже фотография, возможно того самого Ромы.
В итоге я зарегистрировал written.ru. Идею взял у Ромы Воронежского с его сайтами narisoval.ru и napisal.ru, просто перевел слово «написал» на английский.
В 2017 году я обнаружил, что домен parpalak.ru освободился, и зарегистрировал его. Через некоторое время зарегистрировал и parpalak.com, на случай если захочу сделать англоязычный сайт. Кстати, с последним доменом произошла интересная история. Я прописал у регистратора parpalak.com к себе. После чего у меня уже не получилось его добавить. К счастью, никакого контента на сайте по
И вот наступил 2021 год. Государство на полном серьезе принялось «регулировать» интернет (на хабре недавно вышел обзор изменений за последние полгода). Я решил, что пора заняться вопросом информационной безопасности. Не то чтобы я ощутил
- хостинг — в Европе, ничего делать не надо;
- почта — яндексовская, есть риск взлома или потери;
- домены у российских регистраторов — есть риск отключения или потери.
Я решил оставить российские домены у российских регистраторов и принять соответствующие риски. Остальные домены перенес к регистратору NameSilo. Ссылка реферальная: если решите воспользоваться рекомендацией, получу немного денег. Вроде бы у них самые дешевые домены: домен .com чуть дешевле 10 долларов. Кроме покупки можно переносить имеющиеся домены. Для переноса нужно получить у текущего регистратора код авторизации (примерно так же я переносил домены от
В итоге я перенес от российских регистраторов домены редактора математических текстов Upmath, головоломки Арнольда и s2cms.com. Для черновиков физика зарегистрировал новый домен susy.page вместо susy.written.ru. Киноблог и сайт программы с игрой «Жизнь» остались на своих доменах kinoblog.su и life.written.ru, мне их не жалко.
Последним шагом, как и написал в самом начале, сделал основным доменом parpalak.com вместо written.ru. Этим шагом решается и проблема почты. Дело в том, что почтовым сервисом для written.ru я настроил в 2010 году яндексовскую почту для домена, которая перенаправляет все входящие на гугловскую почту. С этим я ничего делать не буду. Просто сделаю основным почтовый ящик на другом домене.
После переезда обнаружилась только одна небольшая проблема — feedly заново показал последние посты. Скорее всего
<guid isPermaLink="true">https://parpalak.com/blog/2021/09/12/smart_vote</guid>При этом feedly проигнорировал поле pubDate и показал записи как свежие. Можно было избежать этой проблемы, если специально для RSS запоминать адреса записей. Но я не думаю, что хоть