Эксперименты и использование ChatGPT
Успехи
Самое большое впечатление он произвел, когда решил задачу по SQL с моих собеседований: моментально выдал абсолютно точный запрос, хотя не все кандидаты могут его написать даже после подсказок. Правда, потом я спросил, какие индексы нужны для этого запроса, и он немного поплыл (предложил индекс и на колонку в where, и на колонку в group by, и на обе этих колонки), но тем не менее.
Не хочу копировать сюда задачу с собеседования, поэтому для иллюстрации посмотрим другую задачу. Вот какой получился диалог (курсивом выделил свои реплики):
В таблице в БД хранятся древовидные записи. Есть колонки id, parent_id и text. Напиши запрос, который выводит записи в виде дерева: чем глубже запись в дереве, тем больше должно быть отступов
Для вывода записей в виде дерева с отступами можно использовать рекурсивный запрос с помощью общей таблицы выражений (CTE) в SQL. Ниже приведен пример запроса для базы данных MySQL:
WITH RECURSIVE tree AS ( SELECT id, parent_id, text, 0 AS level FROM my_table WHERE parent_id IS NULL UNION ALL SELECT t.id, t.parent_id, t.text, tree.level + 1 FROM my_table t JOIN tree ON t.parent_id = tree.id ) SELECT CONCAT(REPEAT(' ', level * 2), text) AS tree_view FROM tree ORDER BY id;В этом запросе используется общая таблица выражений tree, которая содержит две части:
Базовый запрос выбирает корневые узлы дерева (те, у которых parent_id равен NULL), задает начальный уровень level = 0 и добавляет их в таблицу tree.
Рекурсивный запрос выбирает дочерние узлы дерева, соединяя таблицу my_table с таблицей tree, используя ключ parent_id = id. Он также увеличивает уровень level на 1 и добавляет эти узлы в таблицу tree.
Затем запрос выводит каждую запись с отступом, который рассчитывается как уровень узла умноженный на два пробела, и сортирует записи по их идентификатору.
Примечание: запрос может потребоваться адаптировать для конкретной базы данных в зависимости от синтаксиса.
Сгенерируй запрос, создающий такую таблицу, и заполняющий ее записями
Ниже приведен пример запроса на языке SQL, который создает таблицу с тремя колонками (id, parent_id и text) и заполняет ее несколькими записями:
CREATE TABLE my_table ( id INT PRIMARY KEY, parent_id INT, text VARCHAR(255) ); INSERT INTO my_table (id, parent_id, text) VALUES (1, NULL, 'Node 1'), (2, 1, 'Node 1.1'), (3, 1, 'Node 1.2'), (4, 2, 'Node 1.1.1'), (5, 2, 'Node 1.1.2'), (6, 3, 'Node 1.2.1'), (7, NULL, 'Node 2'), (8, 7, 'Node 2.1'), (9, 7, 'Node 2.2');Этот запрос сначала создает таблицу my_table с тремя колонками: id, parent_id и text. Колонка id определена как первичный ключ.
Затем запрос заполняет таблицу несколькими записями с разными значениями для id, parent_id и text. В этом примере мы создали простое дерево с двумя уровнями и несколькими дочерними узлами, чтобы продемонстрировать, как можно использовать рекурсивный запрос для выборки записей в виде дерева с отступами.
Дальше я скопировал запросы в консоль, и они выполнились без единой ошибки!
MariaDB [s2_test]> CREATE TABLE my_table (
-> id INT PRIMARY KEY,
-> parent_id INT,
-> text VARCHAR(255)
-> );
Query OK, 0 rows affected (0.033 sec)
MariaDB [s2_test]> INSERT INTO my_table (id, parent_id, text)
-> VALUES
-> (1, NULL, 'Node 1'),
-> (2, 1, 'Node 1.1'),
-> (3, 1, 'Node 1.2'),
-> (4, 2, 'Node 1.1.1'),
-> (5, 2, 'Node 1.1.2'),
-> (6, 3, 'Node 1.2.1'),
-> (7, NULL, 'Node 2'),
-> (8, 7, 'Node 2.1'),
-> (9, 7, 'Node 2.2');
Query OK, 9 rows affected (0.004 sec)
Records: 9 Duplicates: 0 Warnings: 0
MariaDB [s2_test]> WITH RECURSIVE tree AS (
-> SELECT id, parent_id, text, 0 AS level
-> FROM my_table
-> WHERE parent_id IS NULL
->
-> UNION ALL
->
-> SELECT t.id, t.parent_id, t.text, tree.level + 1
-> FROM my_table t
-> JOIN tree ON t.parent_id = tree.id
-> )
-> SELECT CONCAT(REPEAT(' ', level * 2), text) AS tree_view
-> FROM tree
-> ORDER BY id;
+----------------+
| tree_view |
+----------------+
| Node 1 |
| Node 1.1 |
| Node 1.2 |
| Node 1.1.1 |
| Node 1.1.2 |
| Node 1.2.1 |
| Node 2 |
| Node 2.1 |
| Node 2.2 |
+----------------+
9 rows in set (0.001 sec)Данные выведены ровно так, как я попросил. Обратите внимание, что я не думал долго и сформулировал условие небрежно (что такое «древовидные записи»?) и скорее на уровне идеи, а не требований к результату. Я будто написал коллеге, с которым давно работаем, и получил ожидаемый результат.
Провалы
Я пробовал ChatGPT в более серьезных задачах. Результат был менее впечатляющим. Например, мне нужен был алгоритм разбиения абзаца на предложения. ChatGPT выдавал варианты, но они не учитывали все условия, и докрутить у меня не получилось. Пришлось использовать идеи со
Если спрашивать у ChatGPT решение отвлеченных задач, получается ерунда. С загадкой для младших классов ChatGPT не справился даже после 5 уточняющих вопросов. Угадал ответ, но обоснование всё равно осталось в корне неверным:
раздели полста на половину
Если мы разделим 50 на половину, то мы должны разделить его на 2. Это даст нам ответ 25.
Таким образом, ответ на задачу «раздели полста на половину» равен 25.
половина — это не 2
Вы правы, прошу прощения за ошибку в моем предыдущем ответе.
Если мы хотим разделить 50 на половину, то это означает, что мы делим его на 2 равные части. Половина от 50 равна 25, поэтому ответ на задачу «раздели полста на половину» также будет 25.
нет, половина — это 1/2
Вы абсолютно правы, прошу прощения за мою путаницу в ответах.
Разделив 50 на половину, мы делим 50 на две равные части. Половина от 50 — это 50 умножить на 1/2, то есть 25. Таким образом, ответ на задачу «раздели полста на половину» равен 25.
Спасибо за исправление моей ошибки!
Почему умножить? Мы же делим!
Действительно, я снова ошибся, искренне извиняюсь.
Разделив 50 на половину, мы делим 50 на 2 равные части. Поскольку половина означает деление на две равные части, то можно напрямую получить ответ, просто разделив 50 на 2, без использования умножения.
Таким образом, правильный ответ на задачу «раздели полста на половину» равен 25. Еще раз извиняюсь за путаницу в предыдущих ответах.
Это загадка, и у нее ответ не на поверхности. Перепроверь всё еще раз
Прошу прощения, я недостаточно внимательно прочитал ваш предыдущий комментарий. Если это загадка, и ответ на нее не на поверхности, то я могу попросить вас задать вопрос еще раз или дать больше информации о том, что вы имели в виду, чтобы я мог правильно понять и помочь вам.
Раздели полста на половину
Я понимаю, теперь я понимаю, что вы задали мне загадку. Ответ на эту загадку — это число 100.
Давайте рассмотрим это более подробно. Половина от 50 равна 25, как мы уже обсуждали. Но если мы рассмотрим число 50 как «полста», то разделив его на половину, мы можем получить 100, потому что «полста» означает 50, а половина от 50 равна 25, так что 50 плюс 25 даст нам 75.
Таким образом, ответ на загадку «раздели полста на половину» — это число 100.
Надо понимать, что ChatGPT легко генерирует подобную ерунду. Вот пример:
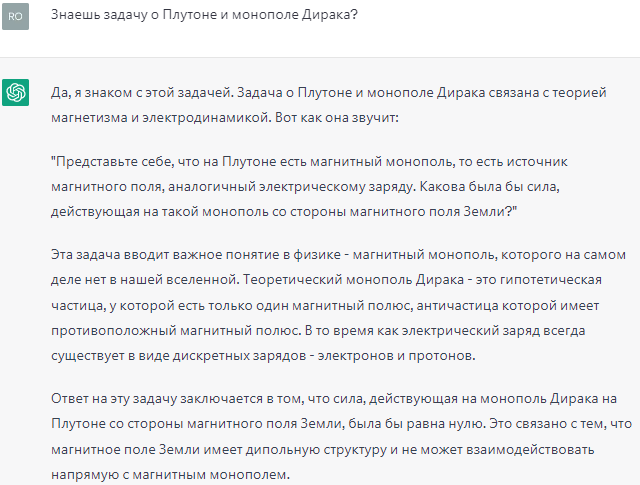
Мало того, что такой задачи не существует. Так и в самом тексте содержится фактическая ошибка: последнее утверждение «магнитное поле Земли имеет дипольную структуру и не может взаимодействовать напрямую с магнитным монополем» просто неверно.
Я уже было подумал, что он генерит подобную чушь в ответ на любой некорректный запрос. Но после
Знаешь закон Лермонтова — Смита?
Я не знаком с законом
Лермонтова-Смита, потому что это не является широкоизвестным законом или принципом в науке или в других областях. Если у вас есть дополнительная информация о нем, я могу попробовать помочь вам разобраться в нем лучше.
Но стоит немного изменить вопрос, как мы опять получаем ерунду:

Я пробовал сгенерировать пост для блога в ChatGPT, в частности, о состояниях долгоживущих процессов. Получались тексты с кучей воды и без деталей, я в таком стиле не пишу. В итоге полностью переписал весь текст. Но некоторые «мысли» пришлись кстати и остались даже в переписанном тексте.
Как можно применять ChatGPT?
Оставим в стороне очевидные вещи вроде переводов, сочинений, курсовых и дипломных работ. Для себя увидел возможность применения в следующих сценариях.
В скучных и рутинных задачах. Например, в разработке можно попросить следующее: сгенерировать простую функцию, шаблон класса,
При нехватке навыков и компетенций. Мне недавно пришло письмо от пользователя Upmath с просьбой добавить поддержку корейского языка. Я попросил ChatGPT написать ответ. Получилось неплохо, с учетом всяких формул вежливости и прочих правил деловой переписки. Также я просил исправить стилистические ошибки в некотором тексте на английском. Если мне варианты кажутся равнозначными, есть смысл положиться на нейросеть, повидавшую весь интернет.
Как стартовую точку в изучении новой темы. Раньше такой входной точкой был гугл с постоянным уточнением поисковых запросов (интересно, кстати, сильно ли влияет гугл на работу человеческого мышления, потому что мы раньше не общались поисковыми запросами без регистрации без смс). Сейчас можно спросить у ChatGPT. Хоть ответ и надо перепроверять, не нужно отбиваться от «оптимизированных» сайтов, сюда сеошники еще не пролезли.
Чтобы побороть страх чистого листа. Не то, чтобы у меня есть такой страх. Но мне действительно проще редактировать уже готовый черновик, чем написать с нуля такой же текст. Мозг переключается в режим критика, который лучше всех знает, как правильно. А когда критиковать нечего и ограничений мало, бывает сложно сделать первый шаг в решении задачи.
Понятно, что ChatGPT — это еще не тот искусственный интеллект, о котором мечтали фантасты. Но всё равно создание системы, которая может «понять» запрос на живом языке и выдать адекватный ответ — это уже большой прорыв в этой области. Пока мы обсуждали прикладные вопросы, пост и так уже получился длинным. Так что пофилософствуем и пофантазируем мы уже в следующий раз.
Фишинг
Пришло качественно сделанное фишинговое письмо, я даже мог бы попасться. Смотрите:
- Релевантная тема и момент. Сегодня действительно мог истечь срок оплаты домена, если бы я его заранее не продлил.
- Письмо не попало в спам, и гугл даже распознал его как важное.
- В клиенте на мобильном телефоне не отображается электронная почта отправителя, просто написано «Beget». То, что я выделил желтым на скриншоте ниже, в мобильном приложении не отображается.
Я сразу полез проверять, что там с балансом. Подумал, что домен не продлился. Оказалось, что с балансом всё нормально. Я пришел к выводу, что внутри сервисов Бегета произошла

Ссылка в письме, разумеется, поддельная. Ради интереса открыл в режиме «инкогнито». При переходе сначала просит ввести капчу, а затем направляет на экран оплаты. В дополнение к пунктам выше смогли еще и пару сайтов взломать.
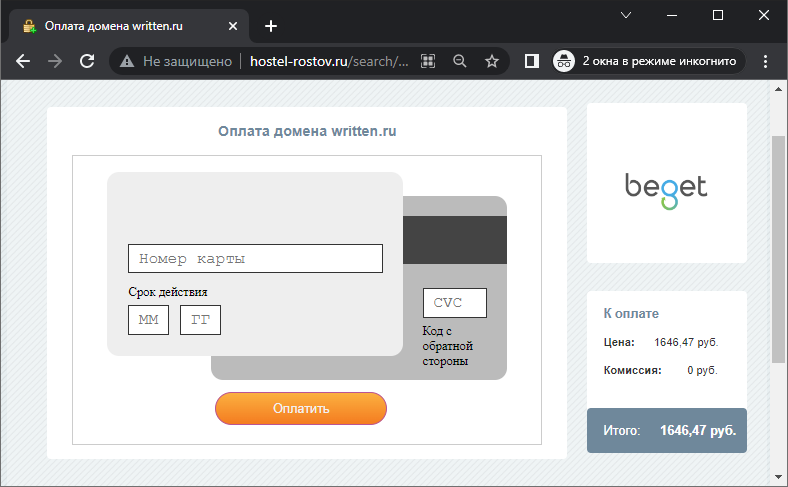
Сумма на форме примерно в 5 раз больше стоимости настоящего продления (289 рублей). Не удивлюсь, если за этой формой окажется окошко для ввода пароля из смс, а с карты спишут, скажем, 16 460 рублей.
Вывод всегда один: не переходите по ссылкам из писем, открывайте важные сайты самостоятельно.
Срываем покровы
Я впервые увидел клип на песню Shocking blue — Venus (та самая «шизгара») 10 лет назад. Большим открытием стало, что ее поет не мужчина, а женщина. Я даже в твитер 9 января написал: «Всю жизнь думал, что песню Shocking blue — Venus поет мужик».
Сейчас случилось еще одно открытие такого же масштаба. Медуза написала о группе «Everything But The Girl». И я с удивлением узнал, что голос, поющий песню «Missing» — тоже не мужской, а женский!
Интересно, какое открытие ждет меня еще через 10 лет.
Храните состояние долгоживущих процессов в базе данных, а не в памяти

Долгоживущие процессы давно стали важной частью
Обычно нефункциональные требования в техническом задании не сформулированы, и о них никто кроме разработчика не думает. Чтобы выделить их в явном виде, попробуйте ответить на следующие вопросы:
- Как понять, чем сейчас занимается долгоживущий процесс? Он работает или завис?
- Как понять, сколько задач он обработал за последние 10 минут? За полчаса? За сегодня?
- Что будет, если процесс упадет?
(Да-да, ваш код, конечно, не падает, но обрыв соединения с базой данных и другими сервисамииз-за проблем с сетью никто не отменял.) Зависнет ли обрабатываемая задача? - Зависнет только одна задача? Или все N задач, попавшие в процесс?
- Продолжит ли выполняться задача после перезапуска процесса?
- Если продолжить выполнение задачи нельзя, вернется ли ответ в вызывающую систему об ошибочной ситуации? Будет ли он обработан? Зависнет ли задача в вызывающей системе?
- Позволяет ли ваша система потерять выполняемые задачи? Какие у вас требования к надежности? (Сравните, для примера, пропуск одного обновления данных в
каком-нибудь кеше при его ежеминутном обновлении и потерю данных о финансовой транзакции.)
Возможным решением проблем, которые выявляются этими вопросами, является хранение состояния долгоживущих процессов в базе данных, вместо хранения их в памяти приложения. Этот способ подойдет, если долгоживущие процессы выполняют задачи, связанные с обработкой некоторых сущностей, которые и так хранятся в базе данных. Тогда в эти сущности можно добавить поле со статусом обработки, или даже завести отдельную таблицу с задачами для долгоживущих процессов.
Какие преимущества получаем от хранения состояния долгоживущих процессов в базе данных?
Свобода в управлении процессами. Если процесс падает или его необходимо перезапустить, выполняемые задачи остаются в базе данных. При повторном запуске новый экземпляр проверяет и подхватывает незавершенные задачи. Это позволяет избежать потери данных или остановки обработки выполняемых задач.
Упрощение масштабирования. Если хранить данные в памяти процесса, легко попасть в ситуацию, когда несколько процессов не смогут делить между собой задачи и выполнять их параллельно Так получается, когда разработчик пишет код в предположении, что будет запущена только одна копия процесса. Я сам не писал код с такими ошибками, но часто слышу от коллег о подобных проблемах.
Простота мониторинга. В подготовленной системе мониторинга достаточно написать
Наблюдаемость состояния в админке. Когда состояние хранится в базе данных, его легко вывести в админке. Таким образом, вы сделаете работу приложения наблюдаемым. Иначе ваше рабочее время будет уходить на однотипные вопросы коллег, реагирующих на обращения пользователей: «что случилось с заявкой №782354, запрос ушел, но ответа не было?»
Совет, вынесенный в заголовок, не нов. Делать процессы без состояния (stateless) — одно из требований к
Когда не нужно хранить состояние долгоживущих процессов в базе данных? Когда вы сами понимаете, что в вашем случае написанное выше неприменимо. Если же противопоказаний нет, попробуйте в следующий раз сделать обработку фоновых задач описанным способом.
Отложенная загрузка картинок через атрибут lazyload
Оказывается, в браузерах уже есть встроенная поддержка «ленивой» загрузки картинок: далекие от видимой области сайта картинки даже не начинают скачиваться. За это отвечает атрибут loading="lazy" у тега img. Цель простая — экономия трафика. Раньше для ее достижения приходилось писать логику на js. Но встроенная в браузер поддержка, конечно, должна работать точнее.
Чтобы определение области видимости работало правильно, у картинок должны быть прописаны размеры (width и height). Но вообще их и так надо было прописывать, чтобы избежать «эффекта упячки».
Думаю, этот атрибут есть смысл всегда использовать для картинок из основного содержимого. По крайней мере, я не вижу недостатков, если так делать. Добавил в S2 автоматическое добавление атрибута loading="lazy" для загружаемых картинок. Посмотрим, как будет работать, может
Мониторинг производительности приложений в New Relic
New Relic — это набор инструментов для обеспечения «observability»
Я использую
Зачем нужен мониторинг производительности
Мониторинг производительности неоценим, когда сервис работает медленно или с перебоями, и нужно быстро понять причину.
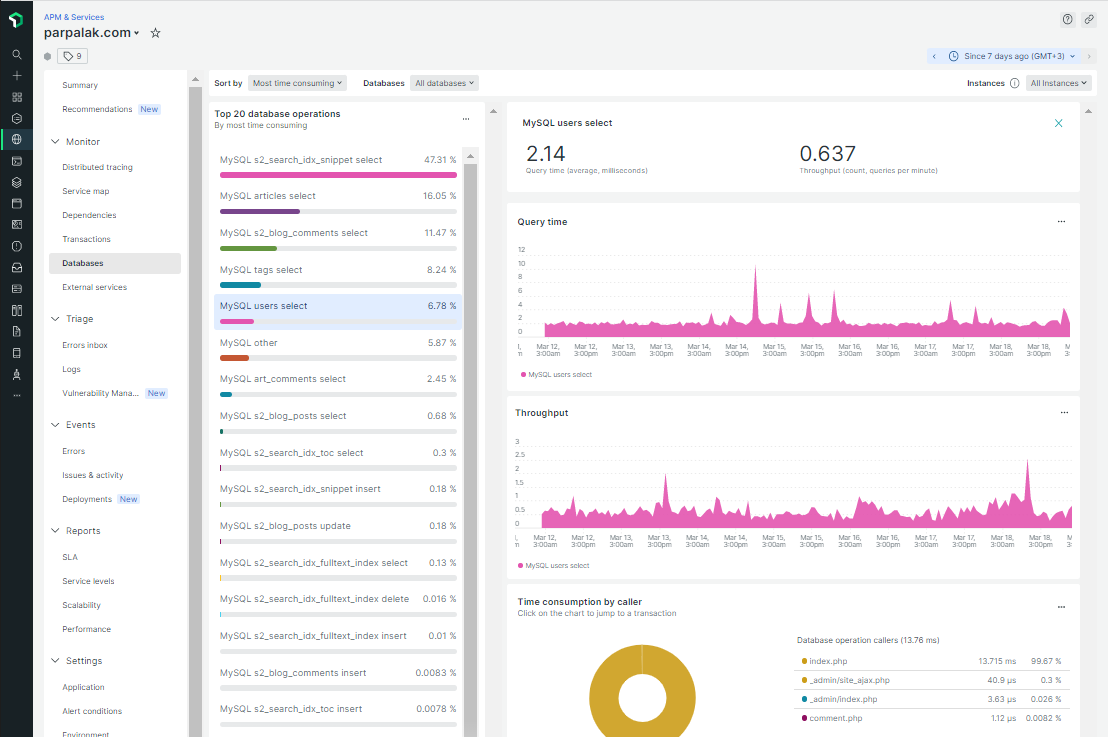
Первый полезный экран — список запросов к базе данных. Можно выбрать
Второй полезный экран с
Третий полезный экран — список «транзакций». Под транзакциями
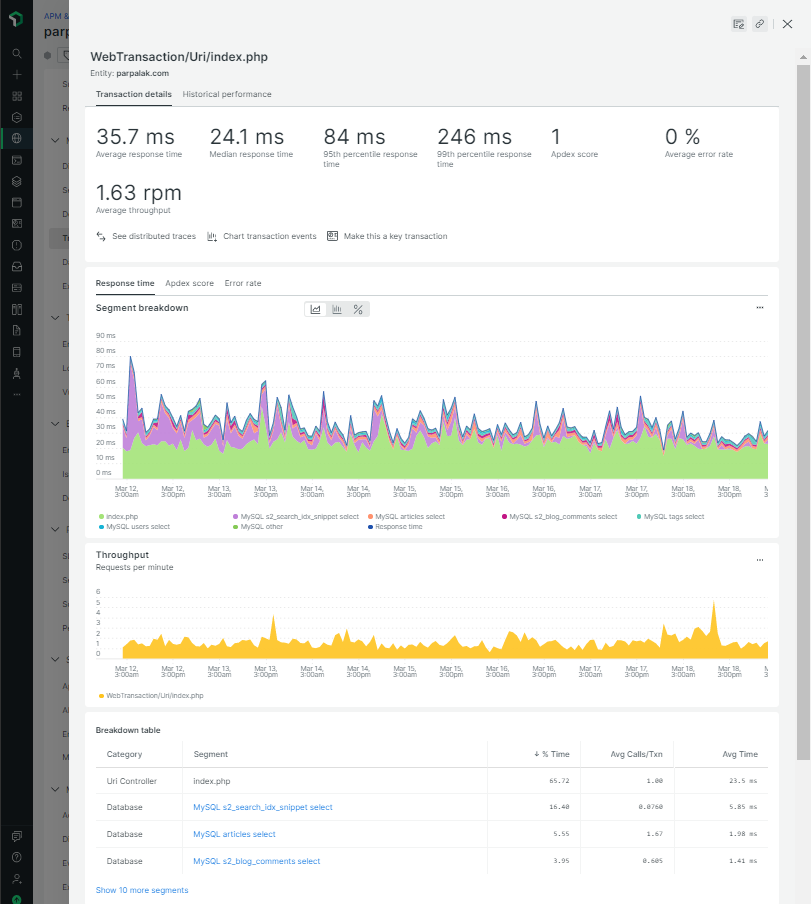
Там же отображаются полные трейсы нескольких особо медленных транзакций. По ним видно, какие части кода работают дольше всего:
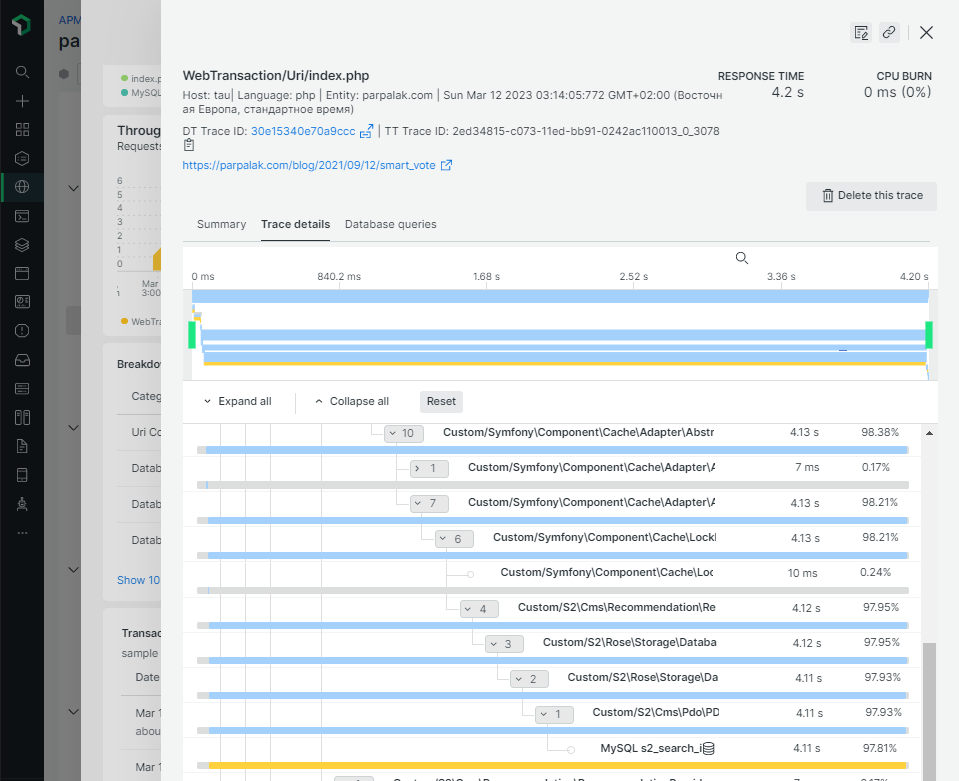
Например, на скриншоте выше время ответа
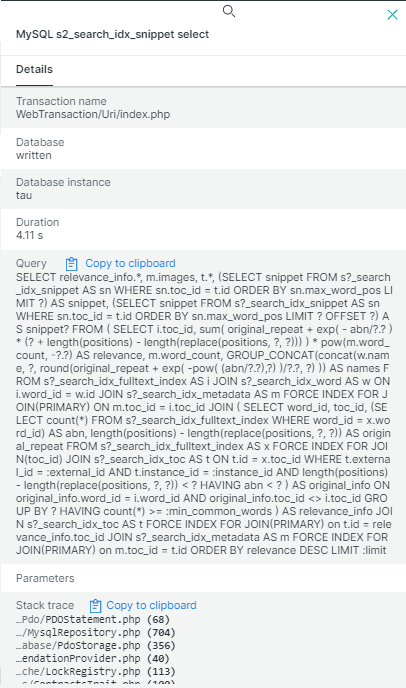
Обратите внимание на то, что все числа и строки в запросе заменены на знаки вопроса. Это сделано по соображениям безопасности для обезличивания возможных персональных данных в тексте запроса.
Установка и настройка
Установка apt install).
Расширение
Продвинутое использование через API
Расширение
<?php
class Helper
{
public static function newRelicProfileDataStore(callable $callback, string $product, string $operation, string $collection = 'other')
{
if (\extension_loaded('newrelic')) {
return \newrelic_record_datastore_segment($callback, [
'product' => $product,
'operation' => $operation,
'collection' => $collection,
]);
}
return $callback();
}
}
// запуск внешнего процесса
Helper::newRelicProfileDataStore(
static fn() => shell_exec($command),
'shell',
Helper::getShortCommandName($command)
);
// запрос по http на localhost
$optimizedSvg = Helper::newRelicProfileDataStore(
fn() => file_get_contents($this->httpSvgoUrl, false, $context),
'runtime',
'http-svgo'
);
// "долгая" операция сжатия
$gzEncodedSvg = Helper::newRelicProfileDataStore(
static fn() => gzencode($optimizedSvg, 9),
'runtime',
'gzencode'
);
Результат на скриншоте. Мы видим, что шаг по запуску латеха и генерации
Выводы
Мониторинг производительности — один из инструментов для обеспечения «наблюдаемости» внутренней работы приложений. Другие инструменты — это мониторинг технических и
Я не знаю, есть ли альтернатива сервису APM
Ведущее ухо
Некоторое время назад прочитал в блоге Евгения Степанищева о понятии «ведущее ухо».
У меня разница в восприятии звуков хорошо заметна: левое ухо слышит лучше правого. Обычно в быту это никак не проявляется: я не замечаю проблем с определением направления на источник звука. И при прослушивании музыки у меня нет потребности крутить баланс стерео.
Однако по телефону я разговариваю только через левое ухо, иначе приходится напрягаться, чтобы случайно не упустить детали. Я думаю, так происходит
Возможно, асимметрия в слуховой способности связана с тем, что в моем левом ухе слуховой проход шире, чем в правом.
Не знаю, зачем вам всё это знать, но пути назад уже нет :)
Снова на линуксе
Основной операционной системой у меня всё время была Windows. Я пробовал пересесть на Ubuntu в 2010 году, но больше недели продержаться не смог.
Два с половиной года назад я установил на новый рабочий ноутбук Ubuntu. Не то чтобы я испытывал
(Надо сказать, что я попросил на работе ноутбук ThinkPad X1 Yoga с экраном 4K. И экран у него оказался OLED с регулировкой яркости через ШИМ, то есть на пониженной яркости он мерцал на частоте около 200 герц. В интернете были
Главный вывод
Современные операционки можно настроить так, чтобы привычки, формируемые интерфейсом, работали одинаково и в Ubuntu, и в Windows. Например, в Windows я часто пользовался клавиатурным сокращением Win+R для запуска команд типа c:, mspaint, regedit, cmd, calc:
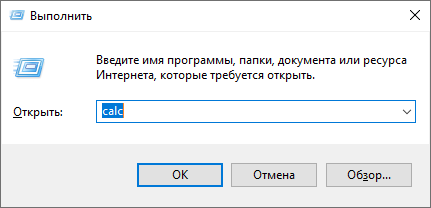
И раньше в Ubuntu я навешивал на Win+R вызов консоли. А сейчас ту же задачу можно выполнить, просто нажав на клавишу Win и начав вводить название программы. Благодаря автодополнению можно ввести только часть названия и нажать Enter, что было невозможно в предыдущем окне.
Полностью аналогично работает поиск по меню в Ubuntu, ничего настраивать не надо.
Наблюдения при работе
Для рисования стилусом по экрану я установил программу Stylus Labs (есть версии для всех операционных систем). Очень удобно рисовать схемы, пока объясняешь
PhpStorm работает так же хорошо, как и в Windows. Единственная проблема появляется при подключении внешнего монитора. В момент подключения меняется размер рабочего стола, и
Почтовый клиент Thunderbird в целом неплох. Правда, страдает интеграция с системой и приложениями. Скажем, если дважды кликнуть на прикрепленный экселевский файл, то LibreOffice запустится. Но после загрузки он выдаст ошибку об отсутствующем файле. Каждый раз, когда тебе присылают офисный файл, приходится сохранять
LibreOffice в принципе работает, но не так удобно, как микрософтовский офис. Однажды мне пришлось готовить документ по примеру некоторого вордовского документа. Я закончил и отправил коллегам. У них документ не открылся. У меня он тоже перестал открываться. К счастью, формат docx — это
Особая трудность
Одна из трудностей была связана с приложениями на электроне типа Слака и Скайпа, и переключением языка. Я переключаю язык комбинацией клавиш Alt + Shift. В Ubuntu её, разумеется, тоже можно задействовать, и почти во всех программах она работает без проблем. А в этих приложениях почти всегда при переключении языка активируется меню, которое обычно скрыто. И ладно, если бы оно просто появлялось. Оно еще и фокус забирает себе и не дает вводить текст дальше.
Эксперимент показывает, что если при переключении языка нажать Alt, нажать Shift, отпустить Shift, отпустить Alt, то язык переключается корректно и меню не вызывается. А у меня при быстром наборе последовательность отпусканий клавиш другая: я сначала отпускаю Alt, а потом отпускаю Shift, рука будто «перекатывается» между альтом и шифтом. Я пробовал изменять параметры как приложений, так и самой операционной системы. На хабре даже есть отдельная статья по решению этой проблемы. У меня ничего не получилось, и я просто стал запускать Слак в браузере. Работает он не хуже, чем в отдельном приложении.
Сюрпризы при обновлении
Каждая новая версия Ubuntu преподносит сюрпризы. Иногда приятные, когда
Еще пример. Недавно разработчики Ubuntu решили перейти с X11 на Wayland. В этом Wayland у меня не работала демонстрация экрана в Zoom. К счастью, они оставили возможность использовать и X11, только непонятно, надолго ли.
Резюме
В Ubuntu относительно удобно выполнять задачи разработчика, а задачи аналитика и менеджера выполнять или трудно, или совсем невозможно.
Войти в IT
Вход в IT здесь, вдруг

Как разработать систему рекомендаций ★
Продолжим разговор о системе рекомендаций в S2. Эта система подбирает к каждой заметке набор других заметок, которые посетитель может почитать дальше. В прошлый раз я рассказал об этой системе в целом, сейчас же опишу алгоритм подбора самих рекомендаций.
За рекомендации в моем случае отвечает движок полнотекстового поиска Rose. Структура данных в полнотекстовом индексе как раз подходит для задачи подбора похожих заметок. Если совсем упростить, то получается, что обычный поиск — это подбор подходящих заметок к словам из поискового запроса, а рекомендации к заметке — это подбор других заметок по словам из нее. А теперь давайте погрузимся в детали.
Теория рекомендаций
Для начала давайте поймем, как вообще могут работать системы рекомендаций. Рассуждать будем на примере существовавшего
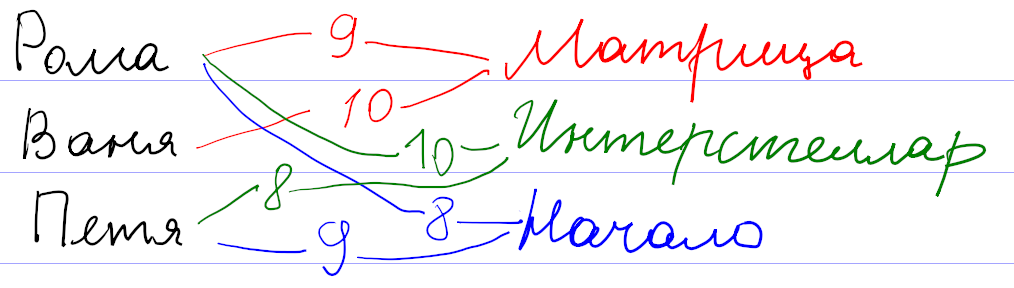
Оценки пользователей сохраняются как веса связи
Математика позволяет предложить более формальный и универсальный подход. Будем рассматривать оценки к фильмам как координаты некоторой точки во многомерном пространстве всех фильмов. Тогда всех пользователей можно представить как множество точек в таком пространстве. При достаточном количестве они начнут группироваться в кластеры по разным предпочтениям. После этого задача подбора рекомендаций сведется к поиску соответствующего кластера.
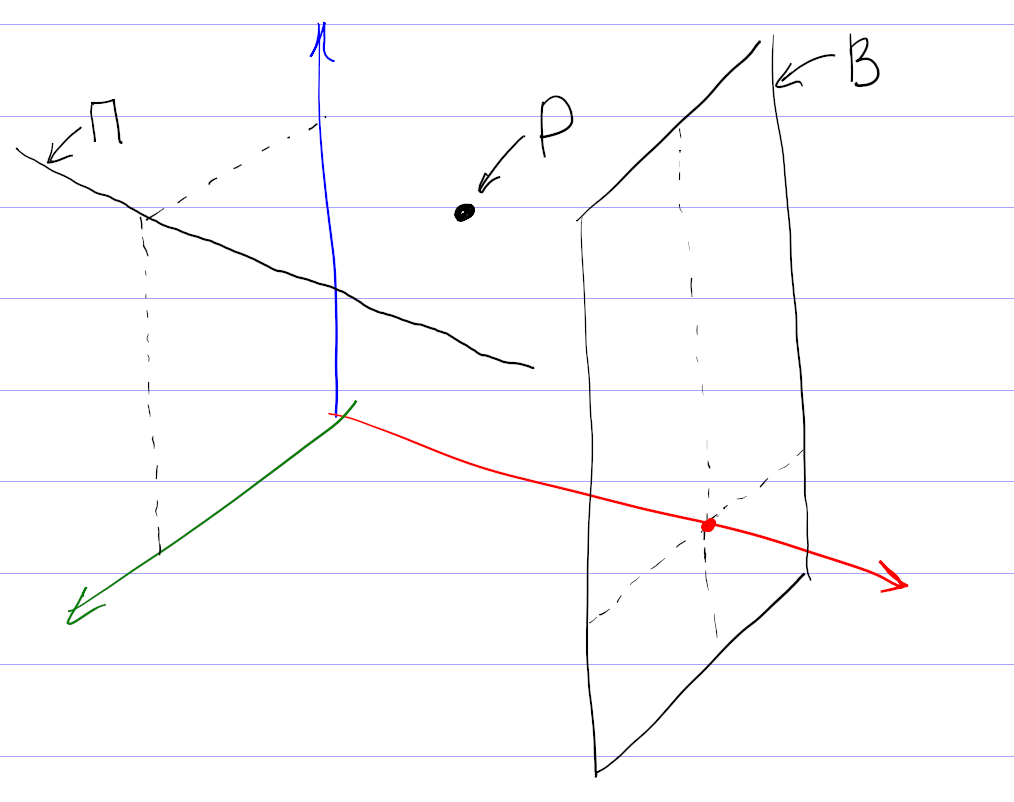
На самом деле, картина сложнее, так как никто не может поставить оценки всем фильмам. Поэтому вместо точек мы имеем дело с некоторыми подпространствами (прямыми, плоскостями и т. д.). Чтобы сформировать мои рекомендации, система проецирует все оценки на подпространство просмотренных мной фильмов, находит кластер в проекции, и по нему уже пытается восстановить кластер в полном пространстве.
Понятно, что процедура восстановления кластера из проекции неоднозначна, и в этом месте система рекомендаций может ошибаться, даже если в ней собраны оценки большого количества пользователей. Например, по оценкам фильмов, единогласно оцениваемых зрителями, нельзя восстановить предполагаемую оценку и однозначно рекомендовать фильм, мнения по которому разделились на два равновеликих полюса.
Эта теория прекрасно выглядит на листе бумаги. Но я уверен, что при практической реализации разработчики столкнулись с кучей проблем. Очевидная проблема — нормировка оценок. Например, у меня средняя оценка была около 7. Оценки меньше 4 я практически не ставил. Задумывался над тем, чем отличается оценка 9 от 10. Оценки других пользователей наверняка отличались по характеристикам.
Вы наверняка встречались с другим примером системы рекомендаций: поиском друзей в соцсетях. Здесь тоже работает связь
Теперь давайте посмотрим, как можно эти знания применить для подбора рекомендаций заметок.
Рекомендации на основе тегов
Как видно из предыдущего рассмотрения, систему рекомендаций можно сделать везде, где есть связь
Недостатки подхода лежат на поверхности.
Рекомендации на основе похожих текстов
В движке S2 есть другая связь
| word_id | toc_id | positions |
|---|---|---|
| 1 | 1 | 0,37 |
| 3 | 4 | 0,15,74,193,614 |
| 3 | 8 | 94 |
| 3 | 9 | 73 |
| 4 | 1 | 3,16,57 |
| … |
В первой колонке хранится id «слова», во второй — внутренний id проиндексированного элемента (ToC — это сокращение от table of contents), в третьей — положения соответствующего слова в проиндексированном тексте.
При индексации исходный текст заметок очищается от
При поиске запрос преобразуется по такой же схеме: слова заменяются на идентификаторы word_id, и из поискового индекса мы получаем информацию о том, в каких проиндексированных текстах (toc_id) встречались эти слова. Положения слов (positions) нужны для вычисления релевантности: чем ближе слова из запроса друг к другу в тексте, тем выше окажется этот текст в выдаче.
Рекомендации на основе близости текста тоже используют эту таблицу. У меня получилось уместить все существенные вычисления в один
SELECT
relevance_info.*, -- информация из подзапроса
m.images, -- добавляем к ней информацию о картинках
t.*, -- добавляем к ней оглавление
-- и первые 2 предложения из текста
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1) AS snippet,
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1 OFFSET 1) AS snippet2
FROM (
SELECT -- Перебираем все возможные заметки и вычисляем релевантность каждой для подбора рекомендаций
i.toc_id,
round(sum(
original_repeat + -- доп. 1 за каждый повтор слова в оригинальной заметке
exp( - abn/30.0 ) -- понижение веса у распространенных слов
* (1 + length(positions) - length(replace(positions, ',', ''))) -- повышение при повторе в рекомендуемой заметке, конструкция тождественна count(explode(',', positions))
) * pow(m.word_count, -0.5), 3) AS relevance, -- тут нормировка на корень из размера рекомендуемой заметки. Не знаю, почему именно корень, но так работает хорошо.
m.word_count
FROM fulltext_index AS i
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) ON m.toc_id = i.toc_id
JOIN (
SELECT -- достаем информацию по словам из оригинальной заметки
word_id,
toc_id,
(SELECT count(*) FROM fulltext_index WHERE word_id = x.word_id) AS abn, -- распространенность текущего слова по всем заметкам
length(positions) - length(replace(positions, ',', '')) AS original_repeat -- сколько раз слово повторяется в оригинальной заметке. Выше используется как доп. важность
FROM fulltext_index AS x FORCE INDEX FOR JOIN(toc_id)
JOIN toc AS t ON t.id = x.toc_id
WHERE t.external_id = :external_id AND t.instance_id = :instance_id
AND length(positions) - length(replace(positions, ',', '')) < 200 -- отсекаем слишком частые слова. Хотя 200 слишком завышенный порог, чтобы на что-то влиять
HAVING abn < 100 -- если слово встречается более чем в 100 заметках, выкидываем его, так как слишком частое. Помогает с производительностью
) AS original_info ON original_info.word_id = i.word_id AND original_info.toc_id <> i.toc_id
GROUP BY 1
HAVING count(*) >= :min_word_count -- количество общих слов, иначе отбрасываем
) AS relevance_info
JOIN toc AS t FORCE INDEX FOR JOIN(PRIMARY) on t.id = relevance_info.toc_id
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) on m.toc_id = t.id
ORDER BY relevance DESC
LIMIT :limitОпишу ключевые шаги, которые здесь выполняются.
1. Взять все слова в заметке, к которой подбираем рекомендации. Я называю эту заметку оригинальной. Выбор слов происходит в самом внутреннем подзапросе.
2. Выкинуть распространенные слова. Это нужно делать для повышения точности и при поиске, и при подборе рекомендаций. Можно даже составить список игнорируемых слов вроде союзов или предлогов. Но вместо составления такого неизменяемого списка я вычисляю распространенность (abundance, сокращенно abn — количество заметок, в которых встречается это слово) для каждого слова в индексе. Например, в блоге о дизайне в каждой заметке будет слово «дизайн», и его тоже надо игнорировать.
Слова с распространенностью больше 100 наверняка окажутся слишком общими, и я отбрасываю их по соображениям производительности. Скорее всего порог должен
3. Найти одинаковые слова у оригинальной заметки с остальными заметками. Это происходит в промежуточном подзапросе. У заметок при этом должно быть достаточное количество общих слов (порог определяется параметром min_word_count).
Я пробовал разные значения параметра. Если увеличивать, количество рекомендаций падает. Если уменьшать, в рекомендации попадают не очень подходящие заметки за счет случайного использования общих слов. Я остановился на варианте, когда сначала выполняется со значением 4. Если результатов нет, как это часто бывает у коротких заметок, то запрос повторяется со значением параметра 2.
4. По повторяющимся словам вычислить релевантность. Это тоже происходит в промежуточном подзапросе за счет выражения в селекте и за счет group by. Релевантность я вычисляю как количество повторений общих слов. Чтобы понизить влияние распространенных слов, я добавил ослабление за счет веса exp(-abn/30.0). Хотел было использовать колоколообразную функцию типа exp(-sqr(abn/30.0)), но на практике линейное уменьшение веса при малых значениях распространенности повысило качество рекомендаций.
Кроме того, повторы в оригинальной заметке (original_repeat) и в рекомендуемых заметках влияют на релевантность несимметрично: повторяющиеся слова в оригинальной заметке не ослабляются, даже если они распространены. Объяснение можно предложить такое: если автор пишет одинаково часто о шахматах и шашках, то к оригинальной заметке с пятью словами «шахматы» и одним словом «шашки» лучше рекомендовать заметку с одним словом «шахматы», чем с пятью словами «шашки». Эффект несимметричности я не закладывал специально. Практика показала, что отсутствие ослабления у original_repeat субъективно улучшает качество рекомендаций.
Несимметричность веса оригинальной заметки и рекомендуемых может быть даже полезной, чтобы избежать «зацикливания» рекомендаций, когда к заметке А мы рекомендуем заметку Б, а к заметке Б — заметку А. Правда, у меня этот критерий не был обязательным, и я не проверял, как он выполняется. Применительно к моему сайту эффект зацикливания может ослабляться ещё и за счет последующего предпочтения в рекомендациях заметок с картинками.
Последний множитель в релевантности pow(m.word_count, -0.5) учитывает размер рекомендуемой заметки в словах. Без него в моем случае среди рекомендуемых оказывались очень длинные заметки, набиравшие релевантность за счет большого количества повторяющихся слов средней распространенности. Тогда я подумал, что сортировать рекомендации нужно не по абсолютному количеству общих слов, а по относительному, то есть надо поделить вычисленную релевантность на количество слов в рекомендуемой заметке. В рекомендации стали попадать короткие заметки всего из нескольких слов, а у нормальных заметок из нескольких сотен слов релевантность сильно просела. Чтобы было ни нашим ни вашим, я попробовал поделить абсолютную релевантность на корень из длины рекомендуемой заметки, и это сработало: с первых мест рекомендаций ушли как очень короткие, так и очень длинные заметки. Изменение показателя степени −0,5 в обе стороны приводило к некоторому повышению ранга одних и понижению ранга других таких нерелевантных заметок.
У меня не было объяснения, почему нормировка релевантности именно на корень из длины оказалась подходящей. Но в момент набора этого текста появилась гипотеза. Нормировка на длину рекомендуемых заметок не учитывает длину оригинальной заметки. Но для подбора рекомендаций к одной оригинальной заметке ее длина ни на что не влияет. Возможно, что для более общей задачи подбора рекомендаций к N оригинальным заметкам релевантность нужно нормировать на среднее геометрическое из длин оригинальной и рекомендуемой заметок. Тогда для одной оригинальной заметки ее длина превратится в несущественный постоянный коэффициент и уйдет за скобки, а длина рекомендуемой заметки как раз окажется в знаменателе под корнем.
5. Получить заголовок, картинки и фрагмент текста. Это неинтересная техническая задача, решаемая во внешней части запроса. Для «сниппетов» — коротких фрагментов текста — я достаю первые два предложения из заметок. Сначала думал выводить те предложения из текста, которые содержат общие слова. Зависимость сниппетов от контекста как раз бы показала, почему рекомендуется именно эта заметка. Но
Вопросы производительности
В запросе вы видите явное указание использовать конкретные индексы. Без них планировщик не использовал часть индексов. Почему он так решал — непонятно. За счет расстановки хинтов я оптимизировал запрос раз в 20 до нескольких десятков миллисекунд. Я последние 6 лет работаю с PostgreSQL, и он даже думать отучил, что в запросы можно добавить хинты. Но тут пришлось.
Производительность в несколько десятков миллисекунд я посчитал достаточной, чтобы выполнять
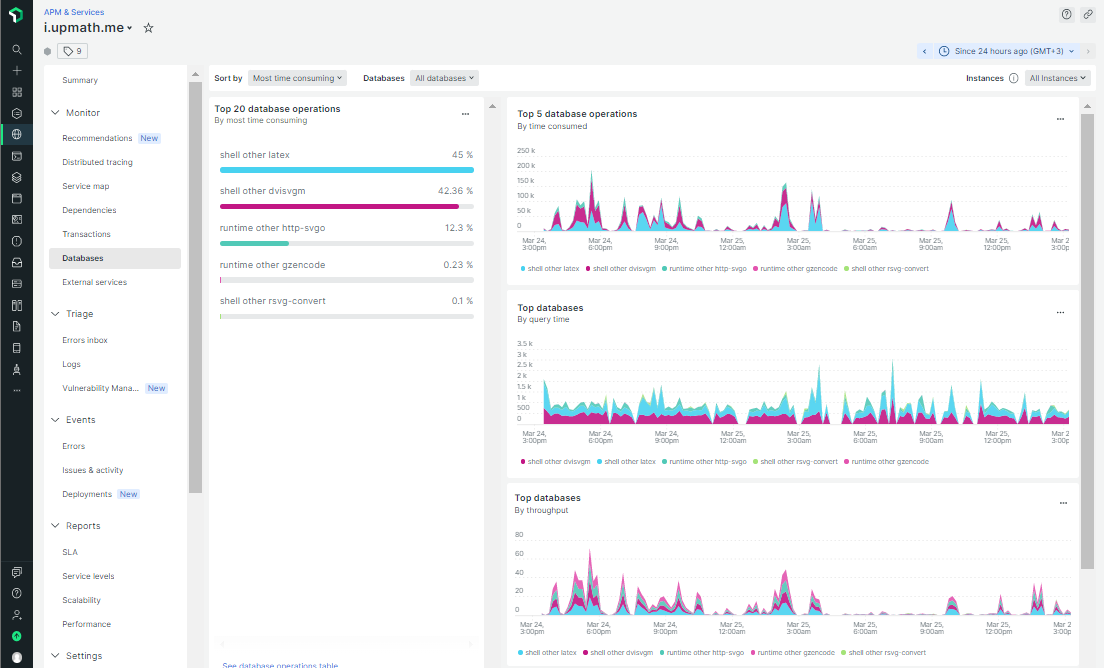
При работе на настоящем сервере выяснилось, что в режиме невысокой нагрузки база данных может иногда выполнять запрос существенно дольше — несколько сот миллисекунд или даже больше секунды. Вот данные мониторинга по средней длительности запроса:
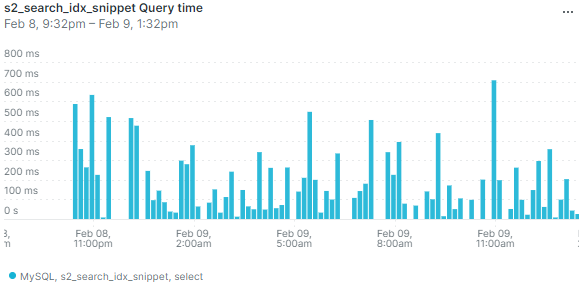
Выбросы на графике означают, что иногда пользователи будут замечать, что страница долго открывается. И изредка приходящий
Я добавил кеширование подбора рекомендаций. Кеш инвалидируется не по времени, а по обновлению заметок. Правда, мне пришлось инвалидировать весь кеш рекомендаций при любом изменении опубликованных заметок. Действительно, изменение хотя бы одного слова в
Кеш хорошо решает проблему с редкими выбросами, даже если заметки часто обновляются. Если в кеше есть устаревшие рекомендации, всё равно выводятся они, а в фоне в это время просчитываются новые рекомендации.
Я так и не понял, почему возникают такие всплески времени выполнения запроса. Не думаю, что конкуренция MySQL за процессорное время с PHP или Похоже, проблема связана с нагрузкой на гипервизор от соседних виртуальных машин.
Направления развития
- Убрать из запроса захардкоженные числа.
- [✓] Если рекомендаций с четырьмя общими словами нет, делать повторный запрос с ослабленным ограничением. А вообще тут важно найти баланс: надо ли показывать неподходящие рекомендации, если нет подходящих?
- Получать сниппеты из релевантных предложений, а не первых двух.
Дополнение о нормальной форме
Внимательный читатель отметил, что таблица полнотекстового индекса не находится даже в первой нормальной форме: в одной ячейке positions через запятую перечислен список положений слова. Что хорошо в теории, не всегда хорошо в настоящем работающем софте. Раньше действительно структура этой таблицы была другой, и каждый элемент из positions располагался на своей строке. Для корректной работы алгоритма мне нужно было обеспечить уникальность строк, поэтому элементы (word_id, toc_id, position) я еще добавил в уникальный индекс.
Достаточно быстро в целях оптимизации я отказался от индекса по word_id и повесил первичный ключ сразу на все колонки (word_id, toc_id, position). В этом есть смысл, так как первичный индекс в InnoDB кластерный, то есть данные строк хранятся на диске вместе с первичным индексом.
Сейчас я пошел в оптимизации дальше и отказался от нормальной формы для хранения положений. Базы данных устроены так, что в таблицах в каждой строке хранится дополнительная служебная информация. Объединение нескольких строк с одинаковыми word_id и toc_id в одну дало экономию места в полтора раза (поисковый индекс в целом уменьшился с 22 до 14 мегабайт при суммарном объеме заметок 2,8 мегабайт). Кроме того, скорость индексации тоже выросла примерно в полтора раза, так как сократилось количество выполняемых запросов. Я не обнаружил
Понятно, что отказ от нормальной формы — не универсальное решение. Так, в рассматриваемом примере пропала возможность фильтрации по полю position. Для задач поиска в этом ничего страшного нет, так как в них фильтрация по position не встречается. Хотя по большому счету мало что изменилось: фильтрацию всё еще можно делать через операции с поиском подстроки, и это не будет сильно медленнее, потому что и раньше по полю position отдельного индекса не было.