Rose
Rose — поисковый движок для полнотекстового поиска на сайтах, с поддержкой морфологии русского и английского языков. Он также предоставляет возможность получения рекомендаций похожих элементов контента.
Некоторые возможности регулярных выражений, о которых мало кто знает
На примере задачи с поиском определенных последовательностей символов в строке расскажу о некоторых не очень известных возможностях регулярных выражений.
Условие задачи
Нужно найти в строке символы i, b, u, d, перед которыми расположено нечетное количество обратных слешей, например \I или \\\b.
Мотивация
Расскажу, откуда появилась эта задача. В свой поисковый движок Rose я добавил поддержку простейшего форматирования в сниппетах: курсив, жирный шрифт, верхние и нижние индексы. Благодаря этому формула
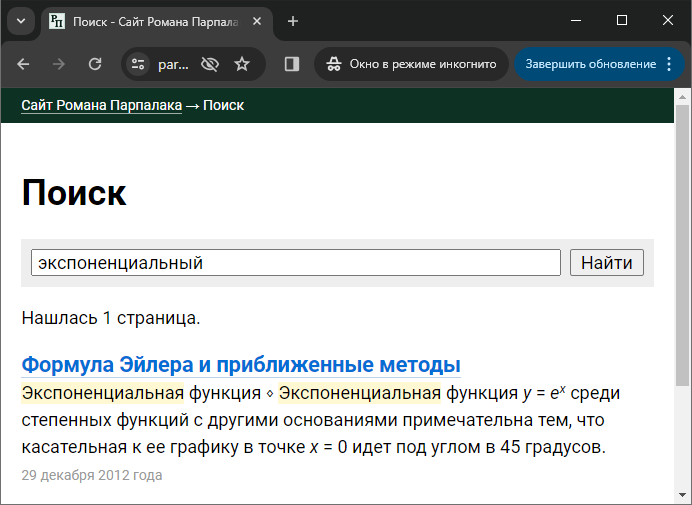
Я не хотел хранить текст сниппетов с частично вырезанными \i включает курсивное начертание, последовательность \I отключает. Аналогично с остальным форматированием. При этом, чтобы хранить сам символ обратного слеша, его нужно продублировать для экранировки (\\). Таким образом, формула из примера выше хранится в сниппетах как \iy\I = e\u\ix\I\U.
Как видно на скриншоте выше, сниппеты собираются из отдельных предложений, а форматирование может распространяться за их границы. Например, я могу выделить курсивом целый абзац, тогда \i будет в начале первого предложения, а \I — в конце последнего. Поэтому важно после разбиения текста на предложения убедиться, что всё открытое форматирование корректно завершено в текущем предложении и перенесено на следующее, и нет завершения неоткрытого форматирования. Для этого как раз и нужна сформулированная задача.
Решение
Я составил такую регулярку: #\\(?:\\(*SKIP)\\)*\K[ibud]#i. Давайте разберем ее по шагам.
- Регулярка начинается с символа обратного слеша. Нужно помнить, что в регулярных выражениях он имеет специальное значение, и сам по себе должен быть экранирован.
- Дальше идет группа
(?:...)без захвата, то есть ее содержимое не попадает в итоговый массив результатов$matches. - Внутри группы находятся два обратных слеша, а сама группа указана с
квантификатором , означающим её повторение любого количества раз, включая нулевое. Таким образом уже разобранная часть регулярки должна срабатывать на нечетном количестве слешей.* - Внутри группы также расположена управляющая последовательность бэктрекинга
(*SKIP). Она обозначает некоторую границу и дает инструкции движку регулярных выражений, чтобы он не переходил эту границу при переборе возможных повторений, задаваемыхквантификатором , а также сразу переходил к ней в исходной строке, если было только частичное совпадение с регуляркой. Без этой управляющей последовательности мы бы получили ложное совпадение на строке*\\iс четным количеством слешей. Действительно, в ней на первом проходе, начиная с первого символа\\i, совпадения нетиз-за четного количества слешей. Но дальше мы получим совпадение, начиная со второго символа:\\i.(*SKIP)же задает границу между вторым слешем и следующим символом, поэтому движок регулярок при работе не будет проверять совпадение со второго символа, а сразу перейдет к третьему. В англоязычной литературе для подобных управляющих последовательностей используется термин Backtracking Control Verbs, среди них есть и другие полезные возможности. - Следующей идет последовательность
\K. Она убирает из результатов общего совпадения всё, что было до нее. Таким образом, в$matches[0]попадет только оставшаяся часть совпадения, без слешей. - Наконец, мы требуем, чтобы после нечетного количества слешей был один из управляющих символов
[ibud]. Так как у регулярки указан модификаторi, совпадение будет в любом регистре.
Если не использовать жемчужину этой регулярки, (*SKIP), можно сочинить выражение с ретроспективной проверкой (lookbehind): #(?<=^|[^\\])\\(?:\\\\)*\K[ibud]#i. Правда, оно будет менее эффективно на строках с обратным слешем. Ну а наивное выражение #(?:^|[^\\])\\(?:\\\\)*\K[ibud]#i будет медленнее на любых строках, так как не начинается с фиксированного символа обратного слеша.
При применении регулярных выражений не нужно забывать о дополнительном экранировании слешей по требованиям синтаксиса языка программирования. Итоговый код на PHP получается таким:
preg_match_all('#\\\\(?:\\\\(*SKIP)\\\\)*\K[ibud]#i', $text, $matches);
foreach ($matches[0] as $match) {
// в $match будет один из символов ibudIBUD
}Мысли о движке сайтов S2
В этом году я сделал несколько доработок своего движка сайтов S2, главная и самая заметная из которых — система рекомендаций. Я бы не стал об этом опять писать, если бы не одно но — до этого крупные доработки в движке я делал больше 8 лет назад. В этой заметке я хочу зафиксировать, как так получилось и что теперь с этим делать.
История
Историю движка можно проследить по тегу «S2». Главная проблема движка в том, что он был полем для моих экспериментов в процессе изучения
С другой стороны, в движке были и удачные находки. Например, шаблон страницы обрабатывается не только после подготовки данных, когда они подставляются в этот самый шаблон, но и до того, чтобы определить, какие именно данные нужны шаблону. Это позволяет гибко управлять функциональностью и не нагружать сервер лишней работой, если она не требуется для отображения текущей страницы. Такую оптимизацию я не встречал в других системах.
В
Со второй частью намерений не сложилось. Были желающие помочь развитию движка, но других активных разработчиков у движка так и не появилось.
Со временем я приобрел достаточный опыт в разработке и стал понимать, насколько тяжело дописывать новый код движка в старой парадигме. Я несколько раз пытался переписывать код с нуля. Сначала без фреймворков с «нормальным» объектным подходом (версия 2.0dev). Потом на микрофеймворке Silex. Потом авторы Silex отказались от его развития, и я подключил Symfony. Все эти попытки сделать версию 3.0 останавливались на том, что надо переделать на новую схему админку и расширения, и для такой объемной работы у меня не было времени и желания.
Одновременно с этим активность на форуме угасла. Авторы некоторых сайтов перенесли их на другие движки. Некоторых сайтов больше нет. Некоторые заброшенные сайты до сих пор работают на S2.
В итоге сейчас у движка больше нет пользователей, на которых надо ориентироваться.
Доработка
Недавно я решил просмотреть все заметки в блоге, удалить устаревшие заметки, актуализировать теги. На удивление некоторые заметки перечитал с удовольствием. Этот процесс вдохновил меня на то, чтобы залезть в код движка и посмотреть, что можно с ним сделать.
У меня получилось за 1 января (обычно бесполезный день) подключить к S2 версии 2.0dev свежую версию поискового движка Rose, и при этом сделать так, чтобы в общем кодовом пространстве движка сосуществовали устаревший код, на который больно смотреть, и новый код, с которым приятно работать. Такой быстрый прогресс открыл дорогу к тому, чтобы сделать уже упоминавшуюся систему рекомендаций.
Также я внес несколько менее масштабных, но не менее желанных изменений. Перенес
Еще подключил codeception — библиотеку для написания автотестов, и стал добавлять эти автотесты. Среди нескольких видов тестов пришлось выбрать приемочные (acceptance). В них выполняются настоящие
Продуктовый подход
Я как единственный оставшийся пользователь движка подошел к нему и своему сайту как к работающему продукту. Вместо того чтобы пытаться переписать движок с нуля на идеальной архитектуре, потратив непонятное количество времени, я сконцентрировался на том, какие фичи могу добавить прямо сейчас. Практика показала, что многое можно сделать в текущей версии, не переписывая ее код с нуля.
Альтернатива — забросить S2 и перейти на другой движок, хотя бы ту же Эгею Ильи Бирмана. Но для этого надо создать свою тему оформления, написать и отладить конвертер заметок, разобраться со старыми адресами URL, пройтись по всем заметкам и убедиться, что ни в одной ничего не сломалось (а ломаться есть чему: у меня есть заметки с нетривиальной версткой вроде рецензии на книгу о фильме «Интерстеллар»). Это значительный объем работы, которую нельзя делать понемногу, мелкими шагами. Мне проще было постепенно доработать свой движок.
Светлое будущее
S2 переехал на гитхаб, откуда его можно скачать. Версию 1.0 я пока что использую, поэтому еще некоторое время буду исправлять баги и проблемы совместимости со свежими версиями PHP. Новых фич в ней не будет. С версии 1.0 можно обновиться до 2.0dev, переработав стили.
Версию 2.0dev буду иногда дорабатывать на досуге. Не планирую свои сайты переводить с неё на
На вопросы возможных пользователей движка я отвечать не планирую. Я не вижу перспектив в том, чтобы у движка появлялись новые пользователи. Сейчас соцсети, облачные платформы и конструкторы сайтов не оставляют движкам типа S2
Как разработать систему рекомендаций ★
Продолжим разговор о системе рекомендаций в S2. Эта система подбирает к каждой заметке набор других заметок, которые посетитель может почитать дальше. В прошлый раз я рассказал об этой системе в целом, сейчас же опишу алгоритм подбора самих рекомендаций.
За рекомендации в моем случае отвечает движок полнотекстового поиска Rose. Структура данных в полнотекстовом индексе как раз подходит для задачи подбора похожих заметок. Если совсем упростить, то получается, что обычный поиск — это подбор подходящих заметок к словам из поискового запроса, а рекомендации к заметке — это подбор других заметок по словам из нее. А теперь давайте погрузимся в детали.
Теория рекомендаций
Для начала давайте поймем, как вообще могут работать системы рекомендаций. Рассуждать будем на примере существовавшего
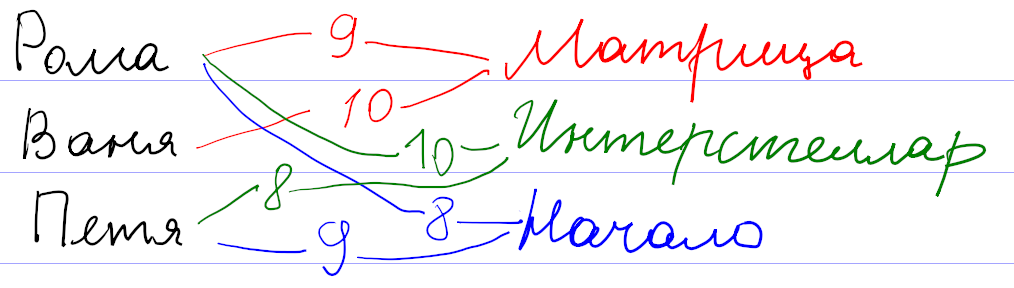
Оценки пользователей сохраняются как веса связи
Математика позволяет предложить более формальный и универсальный подход. Будем рассматривать оценки к фильмам как координаты некоторой точки во многомерном пространстве всех фильмов. Тогда всех пользователей можно представить как множество точек в таком пространстве. При достаточном количестве они начнут группироваться в кластеры по разным предпочтениям. После этого задача подбора рекомендаций сведется к поиску соответствующего кластера.
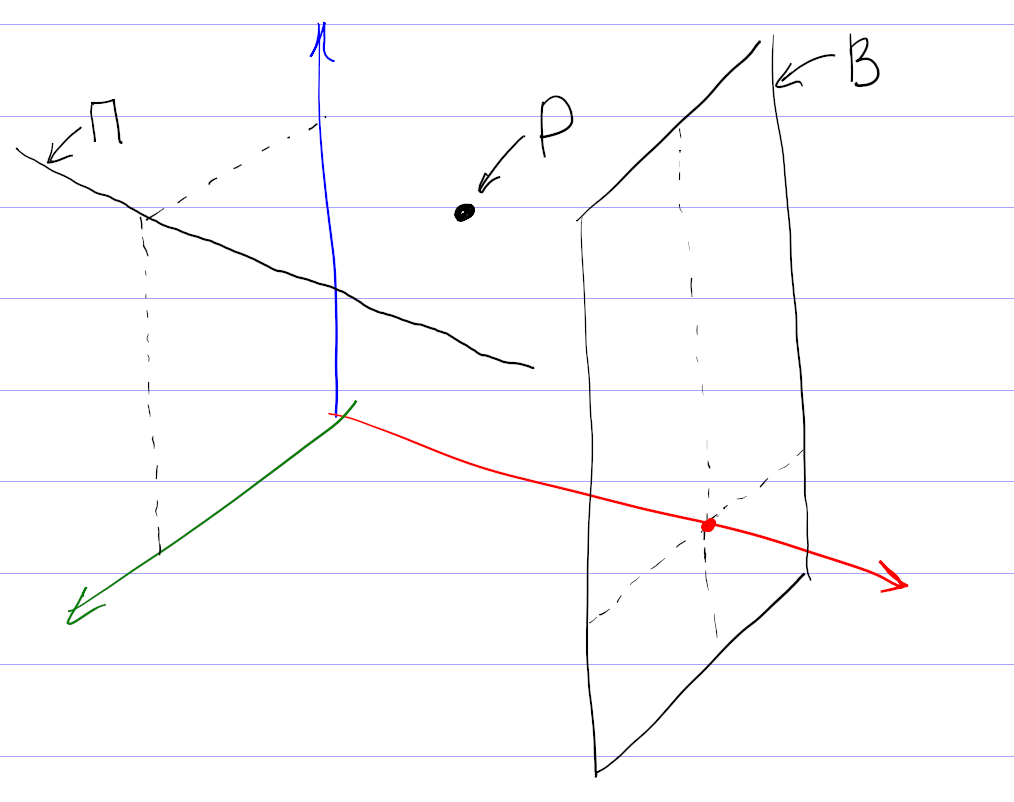
На самом деле, картина сложнее, так как никто не может поставить оценки всем фильмам. Поэтому вместо точек мы имеем дело с некоторыми подпространствами (прямыми, плоскостями и т. д.). Чтобы сформировать мои рекомендации, система проецирует все оценки на подпространство просмотренных мной фильмов, находит кластер в проекции, и по нему уже пытается восстановить кластер в полном пространстве.
Понятно, что процедура восстановления кластера из проекции неоднозначна, и в этом месте система рекомендаций может ошибаться, даже если в ней собраны оценки большого количества пользователей. Например, по оценкам фильмов, единогласно оцениваемых зрителями, нельзя восстановить предполагаемую оценку и однозначно рекомендовать фильм, мнения по которому разделились на два равновеликих полюса.
Эта теория прекрасно выглядит на листе бумаги. Но я уверен, что при практической реализации разработчики столкнулись с кучей проблем. Очевидная проблема — нормировка оценок. Например, у меня средняя оценка была около 7. Оценки меньше 4 я практически не ставил. Задумывался над тем, чем отличается оценка 9 от 10. Оценки других пользователей наверняка отличались по характеристикам.
Вы наверняка встречались с другим примером системы рекомендаций: поиском друзей в соцсетях. Здесь тоже работает связь
Теперь давайте посмотрим, как можно эти знания применить для подбора рекомендаций заметок.
Рекомендации на основе тегов
Как видно из предыдущего рассмотрения, систему рекомендаций можно сделать везде, где есть связь
Недостатки подхода лежат на поверхности.
Рекомендации на основе похожих текстов
В движке S2 есть другая связь
| word_id | toc_id | positions |
|---|---|---|
| 1 | 1 | 0,37 |
| 3 | 4 | 0,15,74,193,614 |
| 3 | 8 | 94 |
| 3 | 9 | 73 |
| 4 | 1 | 3,16,57 |
| … |
В первой колонке хранится id «слова», во второй — внутренний id проиндексированного элемента (ToC — это сокращение от table of contents), в третьей — положения соответствующего слова в проиндексированном тексте.
При индексации исходный текст заметок очищается от
При поиске запрос преобразуется по такой же схеме: слова заменяются на идентификаторы word_id, и из поискового индекса мы получаем информацию о том, в каких проиндексированных текстах (toc_id) встречались эти слова. Положения слов (positions) нужны для вычисления релевантности: чем ближе слова из запроса друг к другу в тексте, тем выше окажется этот текст в выдаче.
Рекомендации на основе близости текста тоже используют эту таблицу. У меня получилось уместить все существенные вычисления в один
SELECT
relevance_info.*, -- информация из подзапроса
m.images, -- добавляем к ней информацию о картинках
t.*, -- добавляем к ней оглавление
-- и первые 2 предложения из текста
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1) AS snippet,
(SELECT snippet FROM snippet AS sn WHERE sn.toc_id = t.id ORDER BY sn.max_word_pos LIMIT 1 OFFSET 1) AS snippet2
FROM (
SELECT -- Перебираем все возможные заметки и вычисляем релевантность каждой для подбора рекомендаций
i.toc_id,
round(sum(
original_repeat + -- доп. 1 за каждый повтор слова в оригинальной заметке
exp( - abn/30.0 ) -- понижение веса у распространенных слов
* (1 + length(positions) - length(replace(positions, ',', ''))) -- повышение при повторе в рекомендуемой заметке, конструкция тождественна count(explode(',', positions))
) * pow(m.word_count, -0.5), 3) AS relevance, -- тут нормировка на корень из размера рекомендуемой заметки. Не знаю, почему именно корень, но так работает хорошо.
m.word_count
FROM fulltext_index AS i
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) ON m.toc_id = i.toc_id
JOIN (
SELECT -- достаем информацию по словам из оригинальной заметки
word_id,
toc_id,
(SELECT count(*) FROM fulltext_index WHERE word_id = x.word_id) AS abn, -- распространенность текущего слова по всем заметкам
length(positions) - length(replace(positions, ',', '')) AS original_repeat -- сколько раз слово повторяется в оригинальной заметке. Выше используется как доп. важность
FROM fulltext_index AS x FORCE INDEX FOR JOIN(toc_id)
JOIN toc AS t ON t.id = x.toc_id
WHERE t.external_id = :external_id AND t.instance_id = :instance_id
AND length(positions) - length(replace(positions, ',', '')) < 200 -- отсекаем слишком частые слова. Хотя 200 слишком завышенный порог, чтобы на что-то влиять
HAVING abn < 100 -- если слово встречается более чем в 100 заметках, выкидываем его, так как слишком частое. Помогает с производительностью
) AS original_info ON original_info.word_id = i.word_id AND original_info.toc_id <> i.toc_id
GROUP BY 1
HAVING count(*) >= :min_word_count -- количество общих слов, иначе отбрасываем
) AS relevance_info
JOIN toc AS t FORCE INDEX FOR JOIN(PRIMARY) on t.id = relevance_info.toc_id
JOIN metadata AS m FORCE INDEX FOR JOIN(PRIMARY) on m.toc_id = t.id
ORDER BY relevance DESC
LIMIT :limitОпишу ключевые шаги, которые здесь выполняются.
1. Взять все слова в заметке, к которой подбираем рекомендации. Я называю эту заметку оригинальной. Выбор слов происходит в самом внутреннем подзапросе.
2. Выкинуть распространенные слова. Это нужно делать для повышения точности и при поиске, и при подборе рекомендаций. Можно даже составить список игнорируемых слов вроде союзов или предлогов. Но вместо составления такого неизменяемого списка я вычисляю распространенность (abundance, сокращенно abn — количество заметок, в которых встречается это слово) для каждого слова в индексе. Например, в блоге о дизайне в каждой заметке будет слово «дизайн», и его тоже надо игнорировать.
Слова с распространенностью больше 100 наверняка окажутся слишком общими, и я отбрасываю их по соображениям производительности. Скорее всего порог должен
3. Найти одинаковые слова у оригинальной заметки с остальными заметками. Это происходит в промежуточном подзапросе. У заметок при этом должно быть достаточное количество общих слов (порог определяется параметром min_word_count).
Я пробовал разные значения параметра. Если увеличивать, количество рекомендаций падает. Если уменьшать, в рекомендации попадают не очень подходящие заметки за счет случайного использования общих слов. Я остановился на варианте, когда сначала выполняется со значением 4. Если результатов нет, как это часто бывает у коротких заметок, то запрос повторяется со значением параметра 2.
4. По повторяющимся словам вычислить релевантность. Это тоже происходит в промежуточном подзапросе за счет выражения в селекте и за счет group by. Релевантность я вычисляю как количество повторений общих слов. Чтобы понизить влияние распространенных слов, я добавил ослабление за счет веса exp(-abn/30.0). Хотел было использовать колоколообразную функцию типа exp(-sqr(abn/30.0)), но на практике линейное уменьшение веса при малых значениях распространенности повысило качество рекомендаций.
Кроме того, повторы в оригинальной заметке (original_repeat) и в рекомендуемых заметках влияют на релевантность несимметрично: повторяющиеся слова в оригинальной заметке не ослабляются, даже если они распространены. Объяснение можно предложить такое: если автор пишет одинаково часто о шахматах и шашках, то к оригинальной заметке с пятью словами «шахматы» и одним словом «шашки» лучше рекомендовать заметку с одним словом «шахматы», чем с пятью словами «шашки». Эффект несимметричности я не закладывал специально. Практика показала, что отсутствие ослабления у original_repeat субъективно улучшает качество рекомендаций.
Несимметричность веса оригинальной заметки и рекомендуемых может быть даже полезной, чтобы избежать «зацикливания» рекомендаций, когда к заметке А мы рекомендуем заметку Б, а к заметке Б — заметку А. Правда, у меня этот критерий не был обязательным, и я не проверял, как он выполняется. Применительно к моему сайту эффект зацикливания может ослабляться ещё и за счет последующего предпочтения в рекомендациях заметок с картинками.
Последний множитель в релевантности pow(m.word_count, -0.5) учитывает размер рекомендуемой заметки в словах. Без него в моем случае среди рекомендуемых оказывались очень длинные заметки, набиравшие релевантность за счет большого количества повторяющихся слов средней распространенности. Тогда я подумал, что сортировать рекомендации нужно не по абсолютному количеству общих слов, а по относительному, то есть надо поделить вычисленную релевантность на количество слов в рекомендуемой заметке. В рекомендации стали попадать короткие заметки всего из нескольких слов, а у нормальных заметок из нескольких сотен слов релевантность сильно просела. Чтобы было ни нашим ни вашим, я попробовал поделить абсолютную релевантность на корень из длины рекомендуемой заметки, и это сработало: с первых мест рекомендаций ушли как очень короткие, так и очень длинные заметки. Изменение показателя степени −0,5 в обе стороны приводило к некоторому повышению ранга одних и понижению ранга других таких нерелевантных заметок.
У меня не было объяснения, почему нормировка релевантности именно на корень из длины оказалась подходящей. Но в момент набора этого текста появилась гипотеза. Нормировка на длину рекомендуемых заметок не учитывает длину оригинальной заметки. Но для подбора рекомендаций к одной оригинальной заметке ее длина ни на что не влияет. Возможно, что для более общей задачи подбора рекомендаций к N оригинальным заметкам релевантность нужно нормировать на среднее геометрическое из длин оригинальной и рекомендуемой заметок. Тогда для одной оригинальной заметки ее длина превратится в несущественный постоянный коэффициент и уйдет за скобки, а длина рекомендуемой заметки как раз окажется в знаменателе под корнем.
5. Получить заголовок, картинки и фрагмент текста. Это неинтересная техническая задача, решаемая во внешней части запроса. Для «сниппетов» — коротких фрагментов текста — я достаю первые два предложения из заметок. Сначала думал выводить те предложения из текста, которые содержат общие слова. Зависимость сниппетов от контекста как раз бы показала, почему рекомендуется именно эта заметка. Но
Вопросы производительности
В запросе вы видите явное указание использовать конкретные индексы. Без них планировщик не использовал часть индексов. Почему он так решал — непонятно. За счет расстановки хинтов я оптимизировал запрос раз в 20 до нескольких десятков миллисекунд. Я последние 6 лет работаю с PostgreSQL, и он даже думать отучил, что в запросы можно добавить хинты. Но тут пришлось.
Производительность в несколько десятков миллисекунд я посчитал достаточной, чтобы выполнять
При работе на настоящем сервере выяснилось, что в режиме невысокой нагрузки база данных может иногда выполнять запрос существенно дольше — несколько сот миллисекунд или даже больше секунды. Вот данные мониторинга по средней длительности запроса:
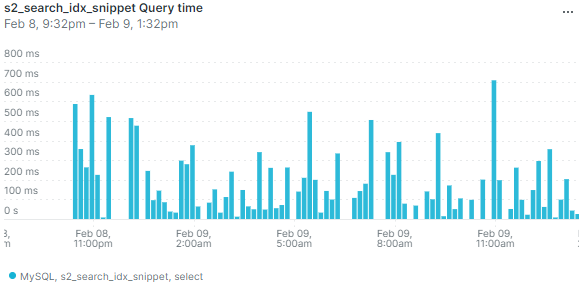
Выбросы на графике означают, что иногда пользователи будут замечать, что страница долго открывается. И изредка приходящий
Я добавил кеширование подбора рекомендаций. Кеш инвалидируется не по времени, а по обновлению заметок. Правда, мне пришлось инвалидировать весь кеш рекомендаций при любом изменении опубликованных заметок. Действительно, изменение хотя бы одного слова в
Кеш хорошо решает проблему с редкими выбросами, даже если заметки часто обновляются. Если в кеше есть устаревшие рекомендации, всё равно выводятся они, а в фоне в это время просчитываются новые рекомендации.
Я так и не понял, почему возникают такие всплески времени выполнения запроса. Не думаю, что конкуренция MySQL за процессорное время с PHP или Похоже, проблема связана с нагрузкой на гипервизор от соседних виртуальных машин.
Направления развития
- Убрать из запроса захардкоженные числа.
- [✓] Если рекомендаций с четырьмя общими словами нет, делать повторный запрос с ослабленным ограничением. А вообще тут важно найти баланс: надо ли показывать неподходящие рекомендации, если нет подходящих?
- Получать сниппеты из релевантных предложений, а не первых двух.
Дополнение о нормальной форме
Внимательный читатель отметил, что таблица полнотекстового индекса не находится даже в первой нормальной форме: в одной ячейке positions через запятую перечислен список положений слова. Что хорошо в теории, не всегда хорошо в настоящем работающем софте. Раньше действительно структура этой таблицы была другой, и каждый элемент из positions располагался на своей строке. Для корректной работы алгоритма мне нужно было обеспечить уникальность строк, поэтому элементы (word_id, toc_id, position) я еще добавил в уникальный индекс.
Достаточно быстро в целях оптимизации я отказался от индекса по word_id и повесил первичный ключ сразу на все колонки (word_id, toc_id, position). В этом есть смысл, так как первичный индекс в InnoDB кластерный, то есть данные строк хранятся на диске вместе с первичным индексом.
Сейчас я пошел в оптимизации дальше и отказался от нормальной формы для хранения положений. Базы данных устроены так, что в таблицах в каждой строке хранится дополнительная служебная информация. Объединение нескольких строк с одинаковыми word_id и toc_id в одну дало экономию места в полтора раза (поисковый индекс в целом уменьшился с 22 до 14 мегабайт при суммарном объеме заметок 2,8 мегабайт). Кроме того, скорость индексации тоже выросла примерно в полтора раза, так как сократилось количество выполняемых запросов. Я не обнаружил
Понятно, что отказ от нормальной формы — не универсальное решение. Так, в рассматриваемом примере пропала возможность фильтрации по полю position. Для задач поиска в этом ничего страшного нет, так как в них фильтрация по position не встречается. Хотя по большому счету мало что изменилось: фильтрацию всё еще можно делать через операции с поиском подстроки, и это не будет сильно медленнее, потому что и раньше по полю position отдельного индекса не было.
Cистема рекомендаций на сайте
Сделал для своего сайта систему рекомендаций. После каждой заметки отображаются аккуратно сверстанные ссылки на похожие материалы. Вот несколько скриншотов, показывающих, как это выглядит.
Пример 1 — антикоррупционный митинг:

Пример 2 — где учиться, на физтехе или физфаке:
Пример 3 — сворачивание кешбека в Бинбанке:
Систему рекомендаций в таком виде сделал Илья Бирман в Эгее — своем движке блогов. В его случае рекомендации к постам формируются на основе тегов. Тогда у меня появилась идея, как можно подбирать рекомендации на основе анализа текстов, без необходимости расставлять теги. Но одно дело — идея, и совсем другое — работающий продукт.
Подбор рекомендаций
Чтобы воплотить идею в жизнь, мне пришлось сделать много подготовительной работы.
Я подключил к моему движку сайтов S2 поисковый движок Rose. s2/search). Но Илья убедил меня, что библиотеке для поиска, как и любому продукту, нужно нормальное имя, и даже предложил несколько вариантов. Название «Ropsen», содержащее первые буквы из Roman Parpalak Search Engine,
Вместе с именем в Розе многое поменялось внутри. Я привел в порядок код, чтобы он следовал правилам хорошего тона для библиотек на PHP: с интерфейсами, инверсией зависимостей и прочими вещами, скрытыми за аббревиатурой SOLID. Кроме того, я сделал реализацию хранилища поискового индекса в MySQL (предыдущая реализация была просто в файле).
Поиск в S2 продолжал работать на старой кодовой базе. Мне казалось, что потребуется много времени, чтобы удалить из
Почему я вообще в заметке о рекомендациях пишу уже четвертый абзац не о рекомендациях, а о поиске? Потому что рекомендации к некоторой заметке на основе ее текста — это, грубо говоря, результаты поиска по словам из этой заметки. Мне удалось написать
Оформление рекомендаций
Чтобы выводить рекомендуемые заметки не просто списком, мне пришлось доработать поисковый движок Rose, чтобы в нем сохранялись предложения из проиндексированных заметок и информация о картинках.
Мне очень понравилось, как выглядят рекомендации у Ильи, и я решил сделать так же. Кроме того, он в своем докладе об автоматическом дизайне рассказал, каким образом работает автоматическая верстка рекомендаций в Эгее. Он подготовил список хорошо сверстанных вариантов и перевел их в некоторый декларативный конфиг с описанием критериев соответствия для каждого элемента верстки (вроде размера и пропорций картинок, длины заголовка и прочего). Дальше для набора рекомендуемых заметок подбирается наиболее подходящий вариант верстки. Обязательно посмотрите видео по ссылке о том, как это всё придумано и работает.
После повторного просмотра видео доклада, которое можно считать подробным и понятным техзаданием, я понял, что не смогу придумать
Тем не менее, я сделал свой декларативный язык. Описал несколько очевидных вариантов верстки, например для пяти рекомендаций: одна крупная рекомендация слева и четыре поменьше справа.
Затем стал смотреть, как имеющиеся рекомендации ко всем подряд заметкам раскладываются по этим вариантам верстки. Выбрал критерий успеха: заметки с картинками не должны выводиться без превьюшек картинок. Если этот критерий не выполнялся, значит, для таких рекомендаций не было подходящего варианта верстки. Я смотрел на них и прикидывал, как надо вывести заметки, чтобы использовать все возможные картинки. Причем делал это не в графическом редакторе, а сразу описывал новый вариант на своем декларативном языке, и он применялся к рекомендациям.
В результате таким способом, никуда не подглядывая, я накопипастил 113 вариантов верстки. Ближе к концу я стал понимать, что это
В процессе мне пришлось изобрести некоторые неочевидные приемы. Например, после определения варианта верстки я сортирую рекомендации по убыванию высоты картинок, а если высота одинакова или картинок вообще нет — по убыванию длины текста. Это нужно, чтобы дыры в верстке появлялись ближе к правому краю, который и так рваный, а не к левому. С дырами получалось забавно: я начал было подбирать длины текста так, чтобы он максимально заполнял дыры. Но рекомендации в некоторых пределах резиновые, а при изменении ширины страницы такие объекты как картинка и текст ведут себя
Еще одно изобретение — отрицательная максимальная длина текста. Она появилась при попытке собрать из картинки и текста блок примерно одинаковой высоты. Скажем, на
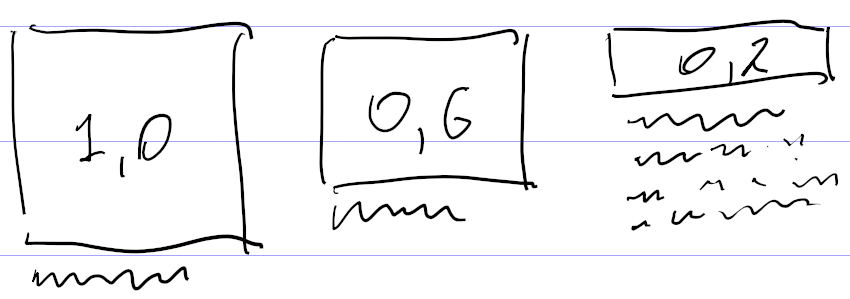
Чтобы не плодить разные варианты одной и той же верстки с таким отличием, я придумал характеризовать текст не только минимальной и максимальной длиной, но и дополнительным коэффициентом, на который умножается «нехватка» высоты картинки для определения дополнительной длины текста. А если картинка с высотой 1,0 тоже подходит, то у картинки с высотой 0,6 за счет добавки обязательно появится текст.
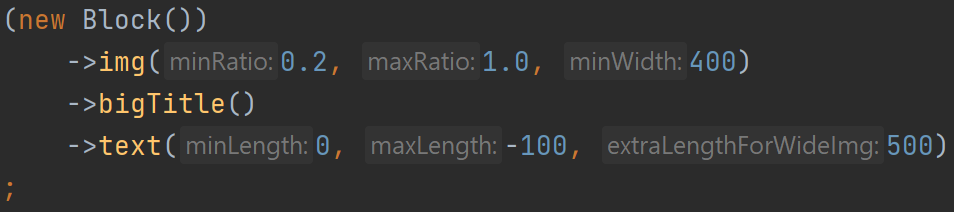
Сначала я хотел сделать дополнительный параметр для отсчета нехватки высоты от 0,6, а не от 1,0. Но потом понял, что того же можно добиться отрицательной длиной текста.
Ограничения рекомендаций и планы на будущее
У Ильи кроме рекомендаций есть еще и перебивки — оформленные таким же образом ссылки в списках записей. Я не стал их делать. В моем понимании рекомендации решают задачу направить посетителя почитать другие записи. Но в списках и так достаточно записей для чтения. Да и технически подобрать ссылки к нескольким записям на одной странице тяжелее, чем к одной записи. Нужно исключать повторы, чтобы одинаковые блоки не повторялись на этой странице.
Сейчас, если в блоке рекомендаций надо вывести текст, я беру
Мастер костылей, или сущности в DOMDocument
Я тут решил потратить некоторое время на собственные проекты. Сейчас перерабатываю движок для поиска Rose. На нем работает поиск на этом сайте, также его использует Илья Бирман в Эгее.
Для извлечения текста из
Как оказалось, DOM API не поддерживает HTML5. Это выливается в практическую проблему с непоследовательной обработкой сущностей HTML. Например, если в исходнике написать & ★, при получении текстового содержимого из & ★. Видим, что первая сущность из HTML предыдущих версий распознается и раскодируется, а вторая из HTML5 — нет. Такие ошибки приведут к искажениям при выводе сниппетов.
Моя первая идея — прогнать текстовое содержимое через html_entity_decode($a, ENT_HTML5);. Действительно, что не доделал встроенный парсер, доделает эта функция. Но проблема в том, что раскодирование неидемпотентно. Если на вход подать &bigstar;, то после DOM API мы получим ★. И на этапе повторного раскодирования мы не будем знать, нужно ли раскодировать ★ еще раз, или нет.
Поиск проблемы в гугле разумного решения не выявил. В классе DOMDocument есть
Для начала нужно все вхождения амперсанда заменить на его сущность:
$text = str_replace('&', '&', $text);После этого DOM API раскодирует копии только одой сущности — этого самого амперсанда. При рекурсивном обходе в текстовом содержимом узлов html_entity_decode($a, ENT_HTML5);.
Уже который раз убеждаюсь, что искусство программиста во многом заключается в умении подобрать нужный костыль. Так и живем.
Пишем объектно-ориентированный код в PhpStorm — В кресле препода №1
В прошлом посте я разрушал мифы о среде разработки PhpStorm. В продолжение я записал скринкаст о том, как в ней писать
Скринкаст рассчитан на людей, не владеющих уверенно ООП. На записи я перевожу фрагмент кода из процедурного стиля в
Содержание:
00:19 Процедурный стиль vs.
01:11 PHP не для процедурного программирования
02:22 ООП в PHP: много рутины
03:05 Задача: показать не только приемы работы в PhpStorm, но и пользу от ООП
04:08 Выбираем код для рефакторинга
05:10 Создаем класс: пространство имен; методы; константы
10:36 Автозагрузка классов через composer
13:28 Разбираем проблемы кода
15:34 Возвращаем вместо массива объект (DTO)
24:29 Избавляемся от глобальных переменных по принципу инверсии зависимостей (dependency inversion)
29:29 Наполняем DTO логикой: __toString
33:16 Рефакторинг
35:14 Наполняем DTO логикой: валидация в конструкторе
39:40 Получился код по принципам SOLID
40:24 Проблема создания сервисов
41:04 Решение с помощью контейнеров зависимостей; подключение Pimple через composer
46:01 Обзор изменений, привнесенных
48:09 Дополнение: подключаем библиотеку поиска Rose, описывая сервисы в контейнере
01:01:38 Подведение итогов
Оптимизация памяти в PHP и функция serialize
Хорошая статья на Хабре про особенности выделения памяти в PHP. Обычно на расход памяти в
Не так давно я писал требовательный к памяти скрипт. Это скрипт поиска, ранняя версия которого используется на сайте правил русского языка, а адаптированная версия перекочевала в мой движок сайтов.
Я немного поколдовал с кодом и в итоге сократил потребление памяти более чем в два раза. Раньше для индексации этого сайта нужно было 32 мегабайта оперативной памяти, а теперь достаточно и 16. Кроме методов из статьи, я применил запись чисел в системе счисления по основанию 36 (перевод осуществляется функцией
Дело в том, что функция
file_put_contents($filename, 'a:'.count($array).':{');
$buffer = '';
$length = 0;
foreach ($array as $word => $data)
{
$chunk = serialize($word).serialize($data);
$length += strlen($chunk);
$buffer .= $chunk;
if ($length > 100000)
{
file_put_contents($filename, $buffer, FILE_APPEND);
$buffer = '';
$length = 0;
}
}
file_put_contents($filename, $buffer.'}', FILE_APPEND);Запись происходит порциями размером около 100 килобайт. Этот код подходит для сохранения в файл массива с большим количеством элементов среднего размера и решает проблему перерасхода памяти функцией