работа программиста
Рассуждаем о вопросах, не связанных с тем, как писать код.
Codeium — нейросетевой помощник программиста
Попробовал в работе Codeium — нейросетевой помощник в написании кода. Его обзор уже был на хабре, так что я просто запишу свои наблюдения, не претендуя на полноту рассмотрения.
Как работает Codeium
Я установил его как плагин к PhpStorm. Для работы он требует войти в аккаунт, но регистрация бесплатна.
Пользователь взаимодействует с плагином двумя способами. Первый — автодополнение. Вы набираете код, останавливаетесь, и в этот момент нейросеть выдает возможное продолжение. Вот я написал название метода, остановился в начале пустого тела, и Codeium вывел серым предполагаемое начало кода:
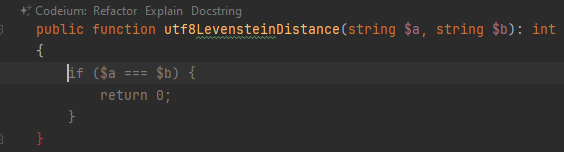
После нажатия на tab и перевода строки нейросеть продолжает сочинять. Вот тут одним махом предлагает написать весь оставшийся код метода:
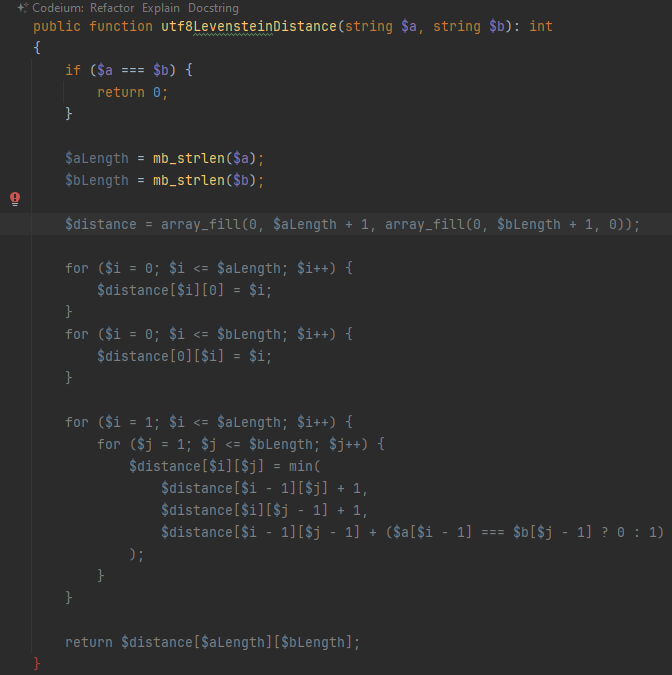
Нейросеть «поняла» из названия метода, что мне нужна версия алгоритма для вычисления расстояния Левенштейна между строками, корректно работающая с кодировкой levenshtein(), но она правильно работает только для однобайтных кодировок). Идея алгоритма оказалась правильной, но с деталями не вышло: сравнение $a[$i - 1] === $b[$j - 1] берет не символы с соответствующими номерами, а байты. После исправления этого фрагмента на mb_substr($a, $i - 1, 1) === mb_substr($b, $j - 1, 1) код заработал правильно.
Второй способ взаимодействия — это чат. Он мне показался туповатым по сравнению с ChatGPT. Я так и не понял, лучше ли работают английские запросы, или можно писать
Главный вау-эффект
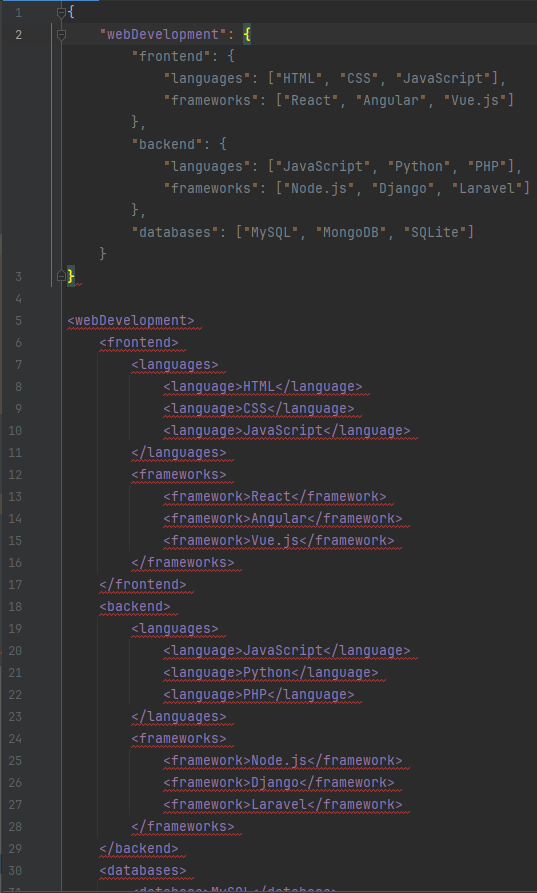
Наибольшая помощь от «искусственного интеллекта» была в переписывании кода и конфигурации из одного формата в другой. Допустим, вы меняете формат
Недостатки
Теперь о недостатках, куда же без них.
Ненативность автодополнения проявляется еще, например, при переименовании. Вот здесь я переименовываю метод так, что PhpStorm заменит его вызовы по всему проекту. На этот режим указывает голубая рамка. Codeium умудряется дописать свое мнение еще и сюда, но сам PhpStorm о нем ничего не знает. Когда я применил подсказку пару недель назад и закончил переименовывать, PhpStorm заменил вызовы по всему проекту на недополненное несуществующее название. Сейчас при попытке воспроизведения tab в режиме переименования просто не работает, подсказка не применяется. То есть Codeium выдает свой вариант, но применить его никак нельзя.
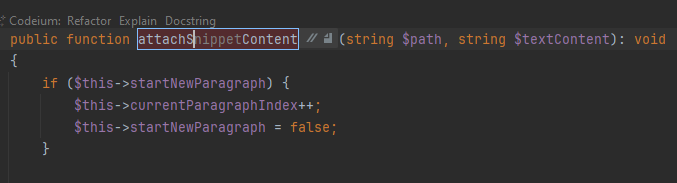
По внешнему виду автодополнения непонятно, что это предложение помощника. Просто серый текст, неотличимый от комментария. В
Еще одна особенность текущего механизма взаимодействия: нет возможности оставить часть предложенного автодополнения, скажем, первые несколько слов. Можно только принять всё целиком и удалить лишнее.
Вывод
В процессе работы перевешивают то достоинства нейросетевого помощника, то его недостатки. Забавно наблюдать, как нейросеть «читает» твои мысли, выдавая ровно тот код, который ты сам собрался написать. Правда, происходит такое не всегда. Когда нейросеть предлагает нужные фрагменты кода, их надо тщательно проверить, как за
В общем, перспективы большие. Пользовательский опыт сейчас страдает. Пробуйте сами.
Да, и не забывайте о вопросах безопасности. Наверняка Codeium отправляет всё редактируемое на свои серверы. Я пробовал его на открытом опубликованном коде своего движка, так что дополнительно ничего «утечь» не может. Если хотите попробовать на работе — проконсультируйтесь с вашим отделом по информационной безопасности.
Воскрешение access-токенов
Недавно Фёдор Борщёв написал о том, что разделение на
У нас на работе для единого входа в приложения (SSO) и получения ролей используется Keycloak. В целом он работает нормально, но иногда подтекает по памяти и начинает отвечать ошибками типа 502. В этот момент приложение тоже становится недоступным: когда истекает время жизни
Чтобы уменьшить влияние недоступности сервиса авторизации на работающее приложение и предотвратить потерю денег, мы придумали переиспользовать истекшие токены и назвали этот прием «воскрешением». Время жизни
Для рассматриваемого
Разумеется, события воскрешения токенов регистрируются в мониторинге, на них установлены уведомления в рабочие чаты. График в мониторинге во время инцидента может выглядеть примерно так:
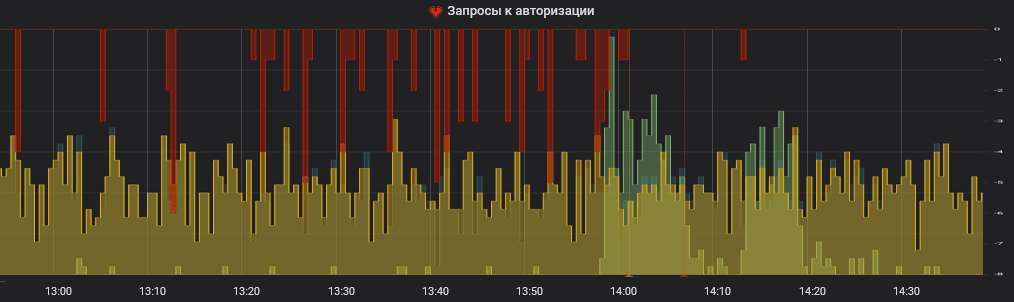
На графике красным отображаются воскрешения токенов, желтым — запросы новых
Кстати, на графике применен еще один полезный прием: ошибочные события, отображаемые красным, выделены на отдельную ось и растут вниз (им формально приписан знак минус). Я сделал так, чтобы у единичных ошибочных событий и у сотен или тысяч успешных событий был разный масштаб, тогда единичные ошибочные события хорошо заметны.
В этой заметке мы рассмотрели некоторые способы обеспечения обеспечения отказоустойчивости и наблюдаемости (observability). Я присвоил ей тег «работа программиста», потому что это действительно работа программиста — подумать об этих нефункциональных требованиях и о том, как их выполнить. К вам никто не придет и не скажет
Храните состояние долгоживущих процессов в базе данных, а не в памяти

Долгоживущие процессы давно стали важной частью
Обычно нефункциональные требования в техническом задании не сформулированы, и о них никто кроме разработчика не думает. Чтобы выделить их в явном виде, попробуйте ответить на следующие вопросы:
- Как понять, чем сейчас занимается долгоживущий процесс? Он работает или завис?
- Как понять, сколько задач он обработал за последние 10 минут? За полчаса? За сегодня?
- Что будет, если процесс упадет?
(Да-да, ваш код, конечно, не падает, но обрыв соединения с базой данных и другими сервисамииз-за проблем с сетью никто не отменял.) Зависнет ли обрабатываемая задача? - Зависнет только одна задача? Или все N задач, попавшие в процесс?
- Продолжит ли выполняться задача после перезапуска процесса?
- Если продолжить выполнение задачи нельзя, вернется ли ответ в вызывающую систему об ошибочной ситуации? Будет ли он обработан? Зависнет ли задача в вызывающей системе?
- Позволяет ли ваша система потерять выполняемые задачи? Какие у вас требования к надежности? (Сравните, для примера, пропуск одного обновления данных в
каком-нибудь кеше при его ежеминутном обновлении и потерю данных о финансовой транзакции.)
Возможным решением проблем, которые выявляются этими вопросами, является хранение состояния долгоживущих процессов в базе данных, вместо хранения их в памяти приложения. Этот способ подойдет, если долгоживущие процессы выполняют задачи, связанные с обработкой некоторых сущностей, которые и так хранятся в базе данных. Тогда в эти сущности можно добавить поле со статусом обработки, или даже завести отдельную таблицу с задачами для долгоживущих процессов.
Какие преимущества получаем от хранения состояния долгоживущих процессов в базе данных?
Свобода в управлении процессами. Если процесс падает или его необходимо перезапустить, выполняемые задачи остаются в базе данных. При повторном запуске новый экземпляр проверяет и подхватывает незавершенные задачи. Это позволяет избежать потери данных или остановки обработки выполняемых задач.
Упрощение масштабирования. Если хранить данные в памяти процесса, легко попасть в ситуацию, когда несколько процессов не смогут делить между собой задачи и выполнять их параллельно Так получается, когда разработчик пишет код в предположении, что будет запущена только одна копия процесса. Я сам не писал код с такими ошибками, но часто слышу от коллег о подобных проблемах.
Простота мониторинга. В подготовленной системе мониторинга достаточно написать
Наблюдаемость состояния в админке. Когда состояние хранится в базе данных, его легко вывести в админке. Таким образом, вы сделаете работу приложения наблюдаемым. Иначе ваше рабочее время будет уходить на однотипные вопросы коллег, реагирующих на обращения пользователей: «что случилось с заявкой №782354, запрос ушел, но ответа не было?»
Когда не нужно хранить состояние долгоживущих процессов в базе данных? Когда вы сами понимаете, что в вашем случае написанное выше неприменимо. Если же противопоказаний нет, попробуйте в следующий раз сделать обработку фоновых задач описанным способом.
Мониторинг производительности приложений в New Relic
New Relic — это набор инструментов для обеспечения «observability»
Я использую
Зачем нужен мониторинг производительности
Мониторинг производительности неоценим, когда сервис работает медленно или с перебоями, и нужно быстро понять причину.
Первый полезный экран — список запросов к базе данных. Можно выбрать
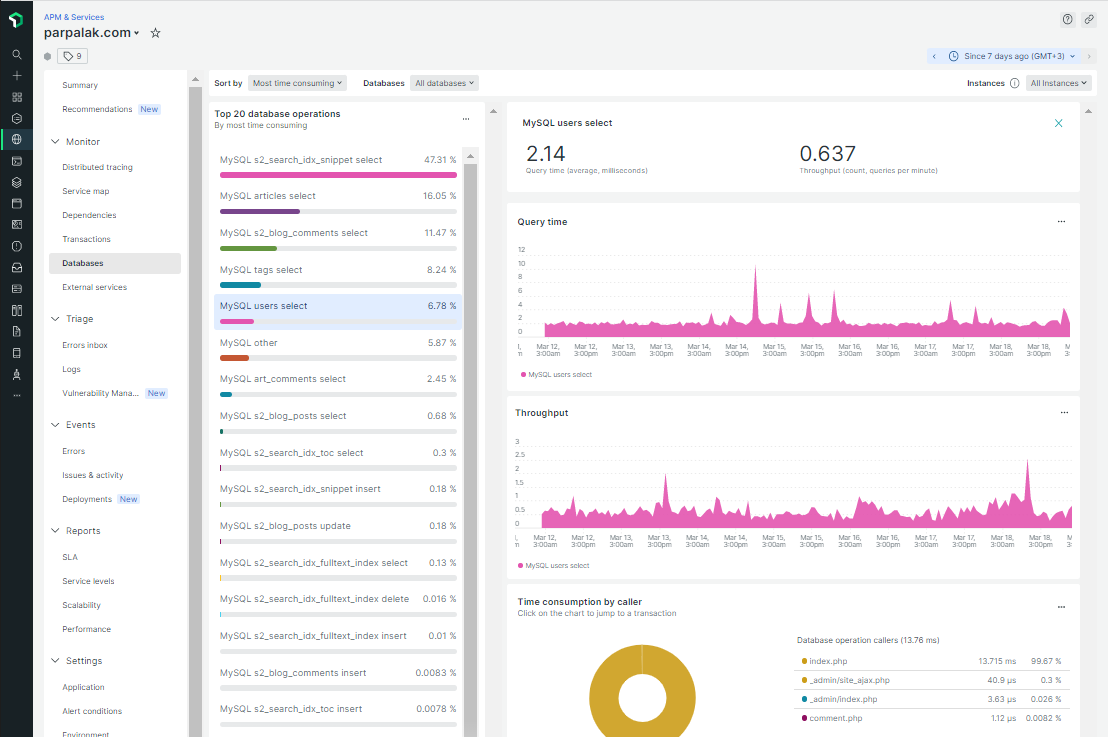
Второй полезный экран с
Третий полезный экран — список «транзакций». Под транзакциями
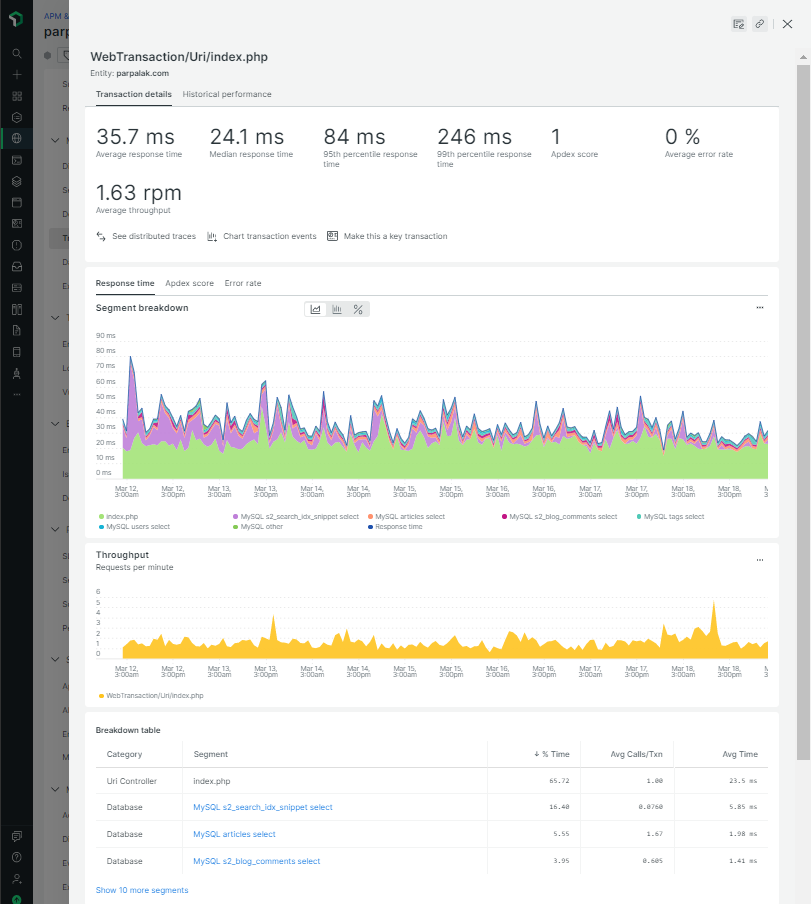
Там же отображаются полные трейсы нескольких особо медленных транзакций. По ним видно, какие части кода работают дольше всего:
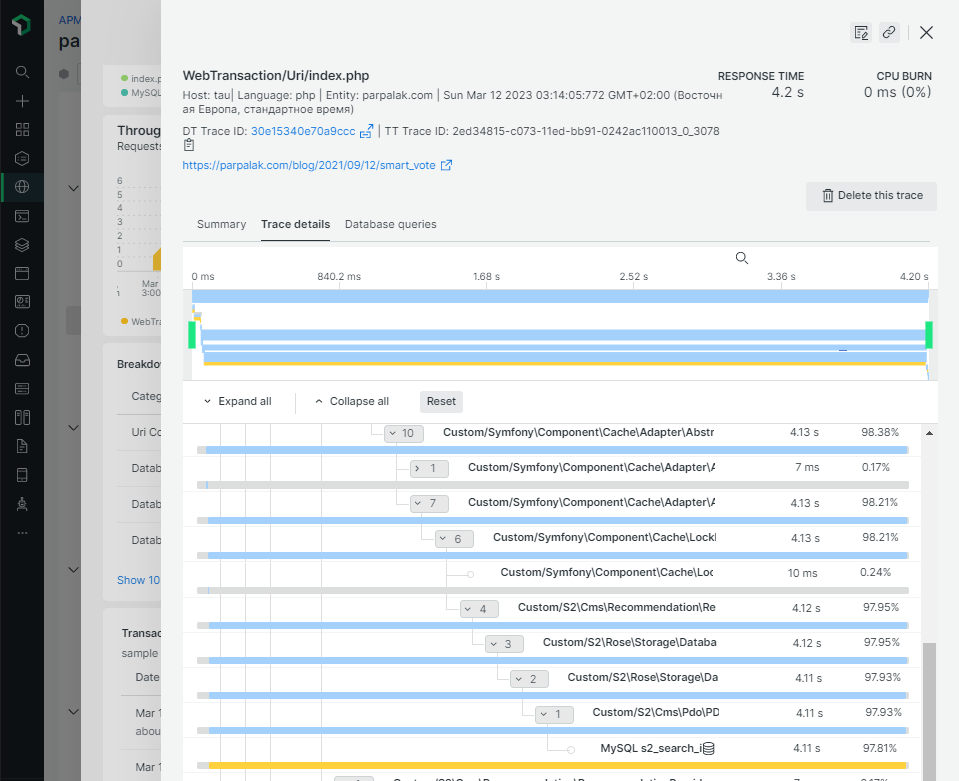
Например, на скриншоте выше время ответа
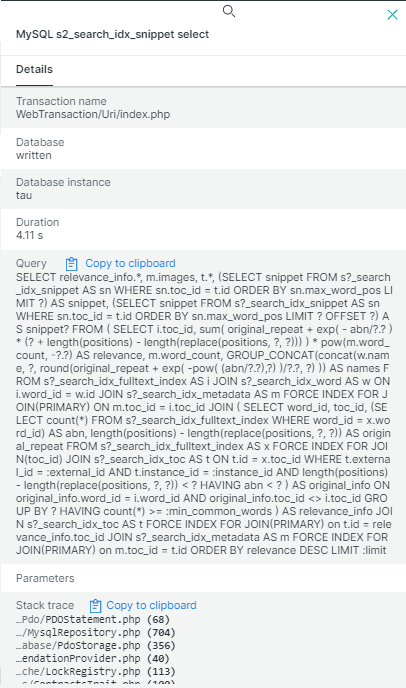
Обратите внимание на то, что все числа и строки в запросе заменены на знаки вопроса. Это сделано по соображениям безопасности для обезличивания возможных персональных данных в тексте запроса.
Установка и настройка
Установка apt install).
Расширение
Продвинутое использование через API
Расширение
<?php
class Helper
{
public static function newRelicProfileDataStore(callable $callback, string $product, string $operation, string $collection = 'other')
{
if (\extension_loaded('newrelic')) {
return \newrelic_record_datastore_segment($callback, [
'product' => $product,
'operation' => $operation,
'collection' => $collection,
]);
}
return $callback();
}
}
// запуск внешнего процесса
Helper::newRelicProfileDataStore(
static fn() => shell_exec($command),
'shell',
Helper::getShortCommandName($command)
);
// запрос по http на localhost
$optimizedSvg = Helper::newRelicProfileDataStore(
fn() => file_get_contents($this->httpSvgoUrl, false, $context),
'runtime',
'http-svgo'
);
// "долгая" операция сжатия
$gzEncodedSvg = Helper::newRelicProfileDataStore(
static fn() => gzencode($optimizedSvg, 9),
'runtime',
'gzencode'
);
Результат на скриншоте. Мы видим, что шаг по запуску латеха и генерации
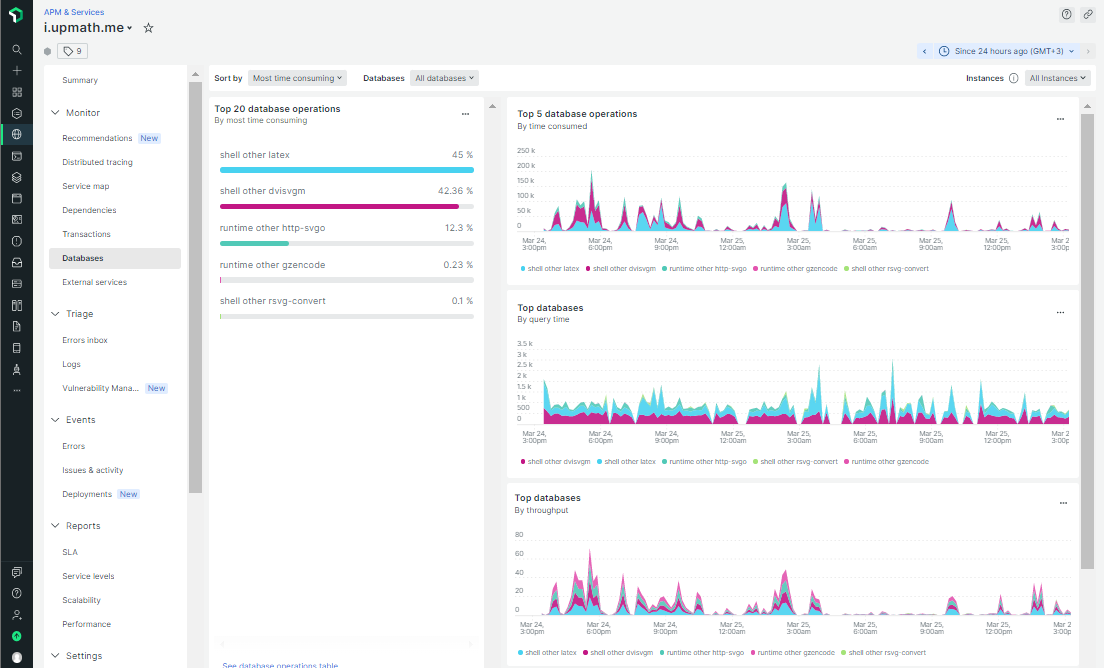
Выводы
Мониторинг производительности — один из инструментов для обеспечения «наблюдаемости» внутренней работы приложений. Другие инструменты — это мониторинг технических и
Я не знаю, есть ли альтернатива сервису APM
Алгоритмическая сложность
Одна из тем, которые я обязательно поднимаю на собеседовании, — это сложность алгоритмов. Кандидату на мои вакансии достаточно назвать сложность наилучшей сортировки —
Если кандидат не дает ответа
Почему важно иметь представление об алгоритмической сложности? Что будет, если писать код без этого представления? Недавно нашелся пример: если на рабочем столе создать 1000 файлов, Windows тратит 20 секунд на открытие главного меню. И всё потому, что
О тестовых заданиях на собеседованиях программистов — В кресле препода №4
Я провел много собеседований. Несколько десятков, или даже около сотни. К сожалению, с самого начала подсчитывать не догадался. Точное число было бы интересным.
Сейчас в очередной раз ищу сильного разработчика (если меня читают такие — напишите). Просматривал резюме и остановился на одном, в котором кандидат написал, что не выполняет тестовые задания бесплатно. В видео ниже я рассказал о том, как открыл его гитхаб, какие выводы сделал, какое тестовое задание выдаю я сам и с какой целью.
Кстати, видео снимал по методу Ильи Бирмана.
Бэкенд и фронтенд в одном репозитории
В советах Бюро обсуждают, нормально ли держать в одном репозитории код фронтенда и бэкенда, или их нужно разнести по разным репозиториям.
Там не упомянули, что сквозную авторизацию на нескольких сервисах с единой точкой входа делать проще, когда
Но самое главное там не написали: структура кода отражает рабочий процесс команды. Если у вас фронтенд- и
Не храните бизнес-логику в базе данных
Современные базы данных не только хранят эти самые данные, но и обрабатывают их с помощью пользовательских функций, хранимых процедур, триггеров. После знакомства с этими инструментами у разработчика возникает мысль перенести часть
Я расскажу, почему в промышленном программировании так делать не надо.
Масштабирование производительности. У приложений и базы данных различные возможности масштабирования при росте нагрузки на систему. Обычные приложения на современных фреймворках легко запустить в несколько копий на разных серверах. А вот базу данных «запустить» на нескольких серверах не так просто. Чтобы снизить нагрузку на чтение, применяют репликацию
Масштабирование разработки. Когда вы разрабатываете систему сами, вы используете любые инструменты на свое усмотрение. Когда вы нанимаете разработчиков, лучше применять стандартные общепринятые инструменты. И баги с боевой системы проще воспроизводить локально, когда
Автоматизация разработки. БД как хранилище данных — стандартная практика. Для упрощения разработки в такой парадигме есть развитые инструменты — библиотеки ORM, которые умеют, в частности, автоматически генерировать скрипты миграции структуры БД. Изменение
Версионирование. Все разработчики научились работать с системами контроля версий кода. Git — стандарт
Тестирование.
Отладка и профилирование. Для отладки и мониторинга серверных приложений существуют инструменты: логирование, отладчики, профилировщики, мониторинг. Искать баги в триггерах и хранимых процедурах вам придется вслепую.
Я помню, как на прошлой работе в CityAds в проекте была одна
Я долго не мог докопаться до настоящей причины, пока не сделал добавление записей из кода приложения, а не из триггера. Оказалось, что вставка иногда не срабатывает
Админы подтвердили, что это известная проблема в MySQL 5.6, но быстро перевести production на 5.7 они не могли. Пришлось переключить тип таблицы с InnoDB на MyISAM. Проблема исчезла.
Не храните
Работа над задачами в скраме
В прошлый раз я рассказал о
Бэклоги продукта и спринта
По скраму задачи на разработку образуют бэклог продукта. Бэклог содержит все требования к продукту и эволюционирует по мере развития бизнеса. За ведение бэклога отвечает владелец продукта, даже если ему в этом помогают другие участники команды. На планировании владелец продукта и команда разработки совместно формируют бэклог спринта, то есть определяют, какие задачи будут взяты в спринт.
На практике бэклог ведется в трекере (редмайн, жира, таргет процесс и пр.). Несмотря на богатство возможностей этих инструментов, запланированные задачи лучше представлять на доске в материальном виде. Когда перевешиваешь настоящую бумажку в колонку «сделано», чувство удовлетворенности от выполненной задачи усиливается.

У доски проходят ежедневные
Предыдущие версии руководства предписывали каждому разработчику команды ответить на стендапе на 3 вопроса:
- Что я сделал вчера, что помогло команде разработки приблизиться к цели спринта?
- Что я сделаю сегодня, чтобы помочь команде разработки достичь цели спринта?
- Вижу ли я
какие-либо препятствия, которые могут помешать мне или команде разработки достичь цели спринта?
В 2017 году в руководство внесли изменение, по которому команда сама определяет формат встречи. Я объясняю это изменение расширением области применения скрама.
Степень детализации требований в бэклоге разная: от подробно проработанных задач на следующий спринт до задач без описания на год вперед. Деятельность по уточнению и оцениванию задач называется product backlog refinement (PBR). Она может проходить в формате регулярной встречи владельца продукта, команды и заказчиков.
Критерии готовности к разработке (DoR)
Зрелая команда берет в спринт только проработанные задачи. Команда сама вырабатывает критерии готовности к разработке (definition of ready, DoR) с учетом особенностей проекта и предметной области. Пример:
Критерии готовности
- Команда разработки понимает
бизнес-ценность - У задачи понятное описание.
- К задаче приложены макеты всех новых экранов.
- В описании задачи указаны критерии приемки.
Если на проработке задачи «сэкономили», то на выяснение требований, согласования и переделки потеряется больше времени.
Почему важно прорабатывать задачи
При написании кода программист принимает десятки мелких решений. Когда он понимает
При работе с дизайнером над макетами даже по простым задачам выясняются тонкие моменты еще до начала разработки, уточняется описание задачи. В противном случае вопросы возникают при разработке, на решение и дополнительное согласование тратится время, задача затягивается.
Критерии приемки проясняют, какие функции требуются заказчику. Просматривая критерии приемки, программист проверяет, всё ли он сделал. А еще критерии приемки — пошаговая инструкция тестировщику.
Команда оценивает только готовые к разработке задачи. Команда объясняет владельцу продукта или заказчику, почему задача не готова, и что надо уточнить.
Зачем оценивать задачи?
Для быстрой обратной связи владельцу продукта и заказчику о сложности задач. У нас в CityAds был образцовый иллюстрирующий случай.
В спринт попала первым приоритетом задача «сделать новую форму добавления рекламодателя». Мы начали ее делать. Как выяснилось, нормальная реализация новой формы добавления затрагивает кроме нашего приложения системы других команд: авторизацию и биллинг. У авторизации не до конца готово АПИ, протокол обмена не зафиксирован, между системами сложное асинхронное взаимодействие. В результате мы не успели сделать все требования этой задачи и часть других задач.
На демонстрации заказчик был недоволен.
— Почему вы не сделали отчет?
— Приоритет формы добавления рекламодателя был выше.
— Мы думали, что вы быстренько сделаете форму и начнете делать отчет. Если бы мы знали, что добавить форму так сложно, отложили бы. Нам нужен отчет.
Оценка задач в часах
Кажется естественным оценивать задачи по предполагаемым затратам времени. Недостаток — оценку в часах сложно дать. Программист
Оценка задач в стори-поинтах
Объем работ больше, если в задаче надо сделать пять экранов, а не два.
Сложность больше, если на форме требуются подсказки у полей, валидация, сложные связи и зависимости между полями.
Риски на неопределенность выше, когда приходится использовать новую технологию или дорабатывать незнакомый код.

Шкала формируется не по первоначальной оценке задач перед выполнением, а по итоговой оценке после (изменение оценок видно на картинке). По мере роста опыта команды, развития проекта шкала эволюционирует: стикеры перевешиваются между колонками, добавляются и удаляются.
В случае затруднений с оценкой команда ищет на шкале похожую по сложности задачу и определяет будущее место для оцениваемой задачи.
Важно ограничить возможные значения
Мы пользуемся картами для покера планирования. После обсуждения задачи команда разработки кидает и вскрывает карты.

Когда оценки расходятся, команда обсуждает причину расхождения. Возможно,
Бывают менее однозначные ситуации.

Здесь потребуется дополнительная проработка задачи: уточнение требований у заказчика, разбиение крупной задачи на несколько частей. Когда команда не знает, как делать сложную задачу, она берет в спринт «ресёрч» — задачу на исследование. Как и любая работа в спринте, ресёрч оценивается в
Как оценивать задачи и планировать спринт?
Если вам ближе идея оценивать в часах, выбирайте часы. Помните только, что при переходе от отдельных задач к спринту важно не планировать впритык, иначе не будет запаса времени на непредвиденные моменты: неточности планирования, поддержку и исправление багов. Запас времени описывается понятием
В начале перехода на скрам в CityAds наша команда начинала с
Чтобы исправить ситуацию, всю поддержку пользователей пустили через систему тикетов и первую линию поддержки. Для решения повторяющихся однотипных запросов к разработчикам стали делать автоматические инструменты. Через несколько месяцев
Если считаете, что разная производительность разработчиков сводит на нет адекватность оценки в часах, выбирайте
Планировать спринт в
Производительность команды меняется от спринта к спринту. На планировании можно учитывать среднее значение за последние несколько спринтов. Чем выше производительность, тем лучше. В погоне за показателями команда может завышать оценки, возможно, даже не осознавая этого. Чтобы избежать инфляции
Мы в CityAds в течение года после внедрения скрама пришли к совмещению двух методов оценки. Оценивали бэклог продукта в
Подзадачи
Проектирование — Коля (1 час)
Бэкенд — Коля (2 часа)
Фронтенд — Леша (4 часа)
Ревью — Рома (1 час)
Тестирование — Настя (2 часа)
Документирование — Коля (2 часа)
Выкладка — Рома (1 час)
После этого трекер рисовал диаграмму загруженности каждого участника. Мы понимали, как перераспределить работу, и успеем ли всё сделать:
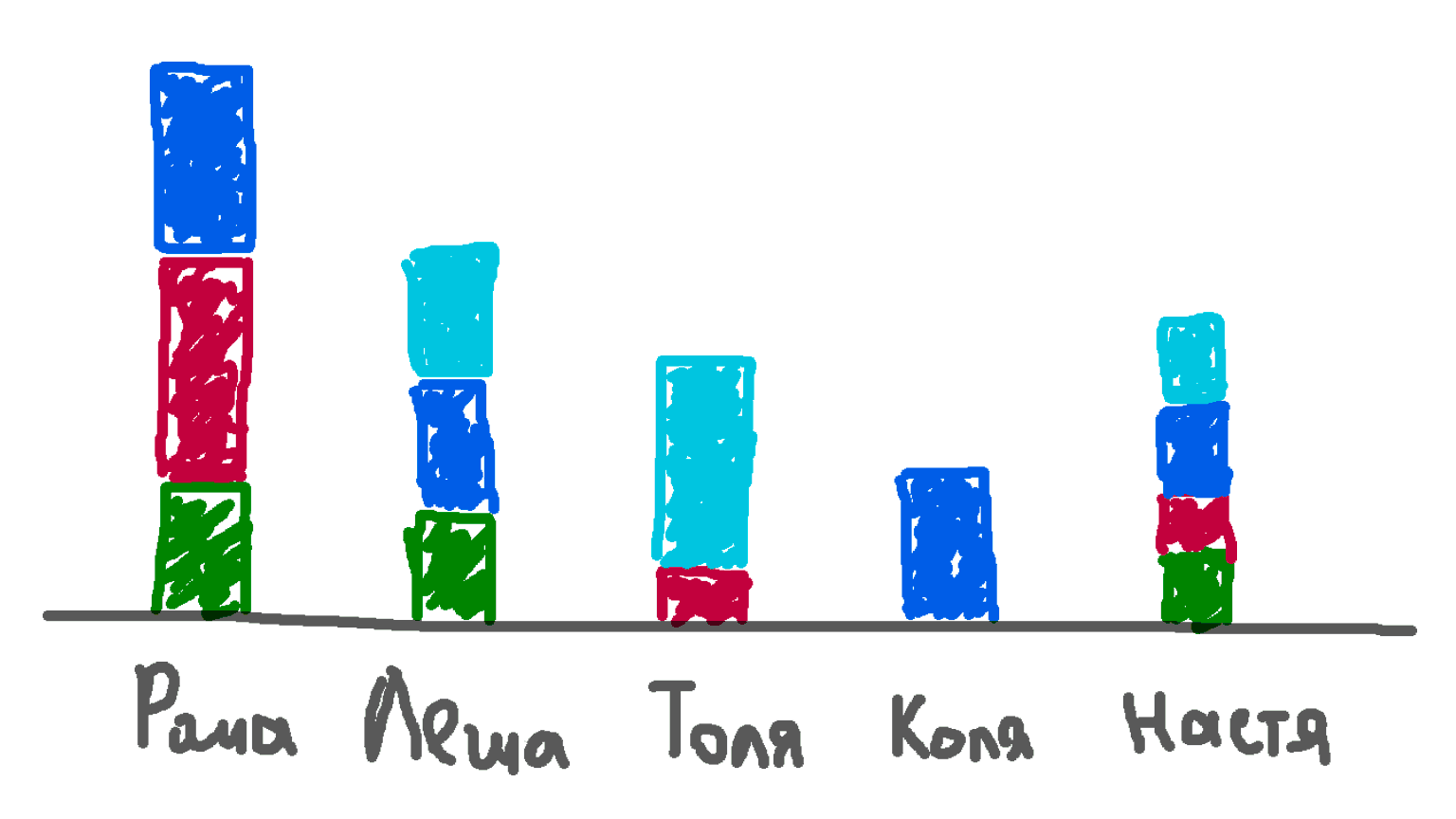
Диаграмма сгорания, впихинг и скрам
На стендапах полезно визуализировать оставшийся объем работ в спринте на диаграмме сгорания
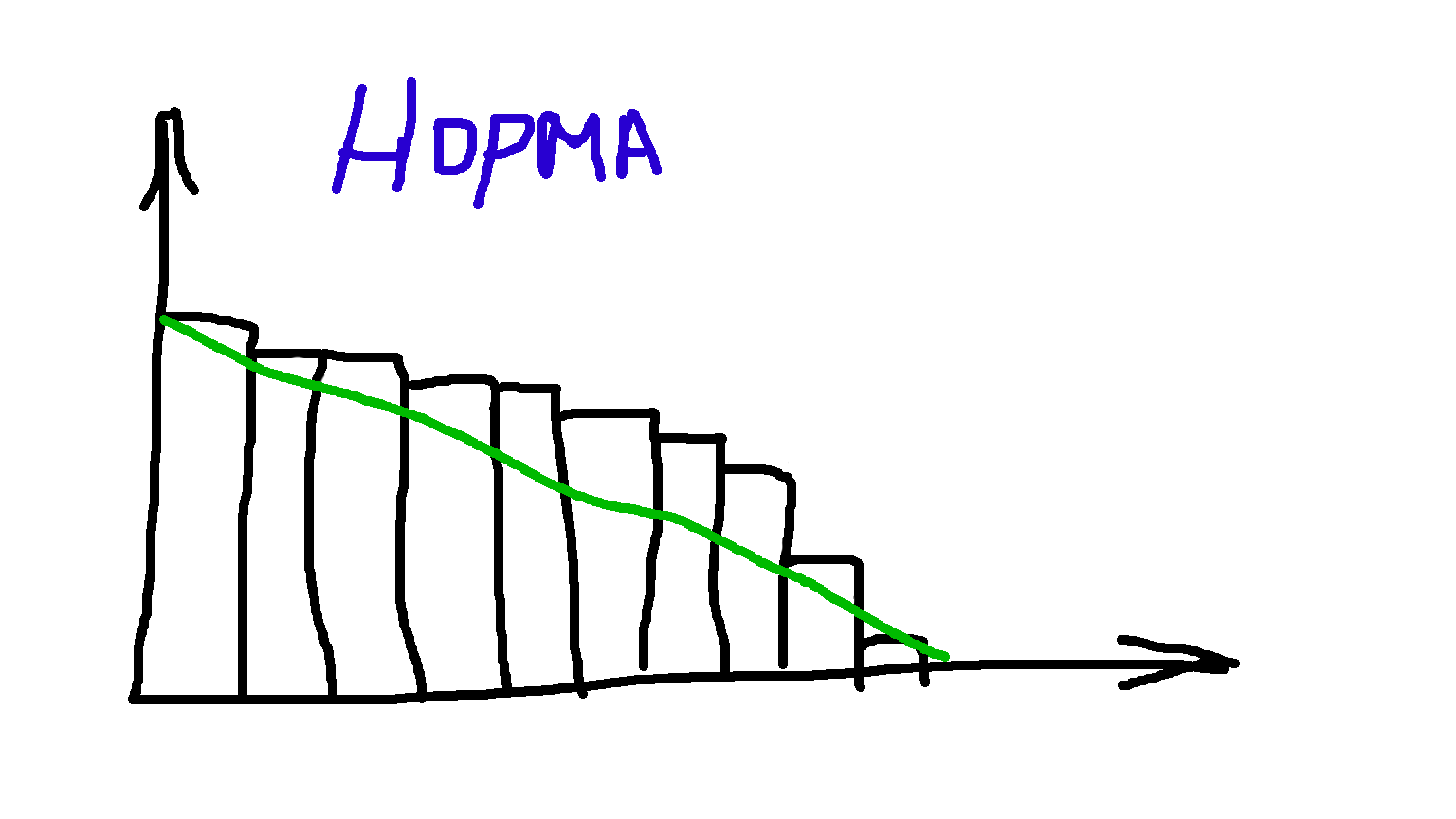
Иногда получается, что график на диаграмме сгорания растет:
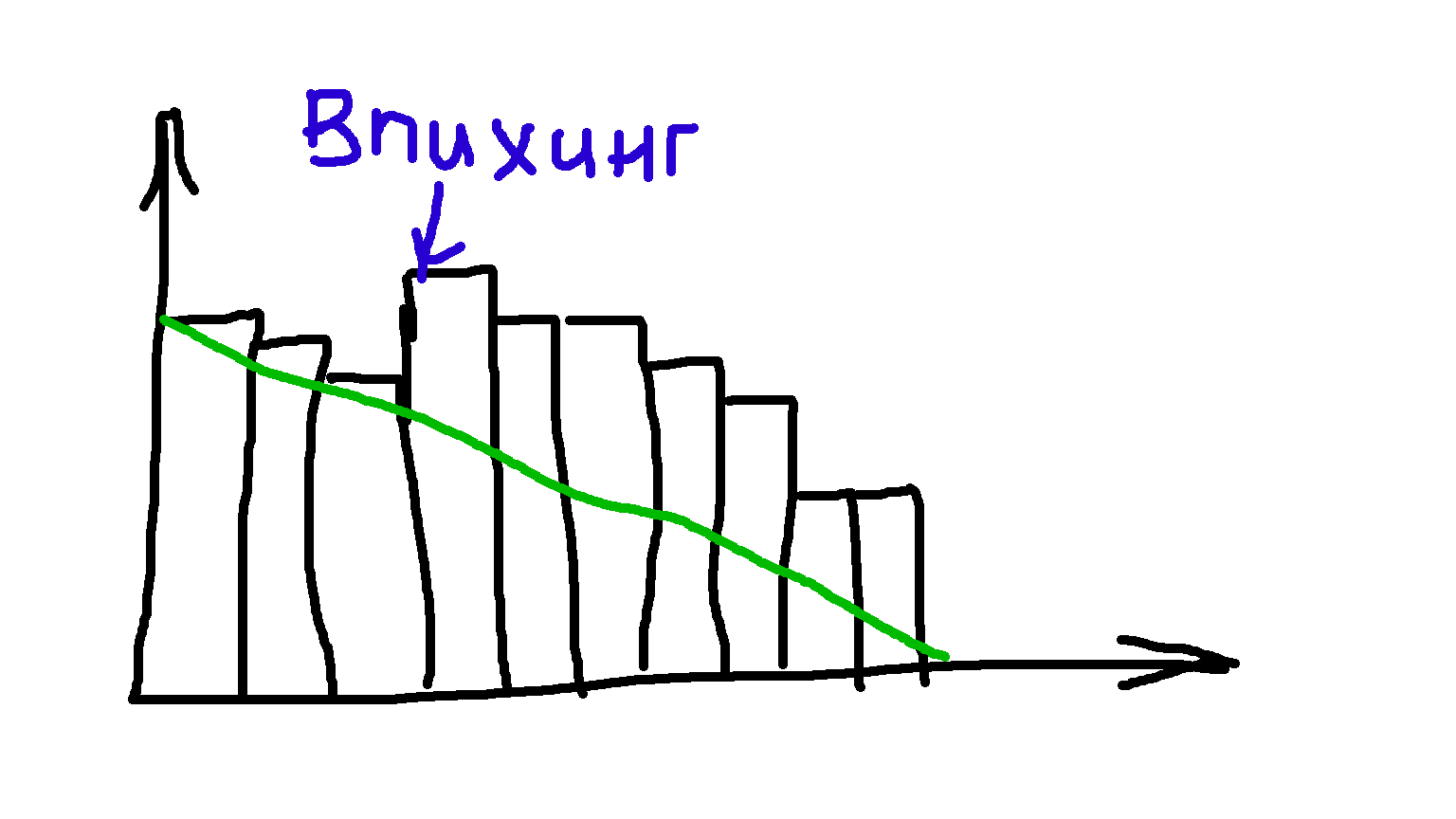
Объем работы вырастает, если команда неправильно оценила одну из задач. Или если произошел впихинг — неприятная история, когда приходит заказчик со срочной задачей. На переключение между задачами тратятся ресурсы,
По скраму в течение спринта никто не может поставить команде разработки
Существует еще одна возможность, о которой любят говорить — остановка спринта. Решение об остановке принимает владелец продукта, если выясняется, что цель определена неверно, а новая цель не может ждать следующего спринта. Команда прекращает любую деятельность в останавливаемом спринте, как будто его и не было, и начинает планирование нового спринта.
Я работал с одно- и двухнедельными спринтами, и в таком режиме остановка была раз в год или два. Наверно, со спринтами длиною в месяц остановка бывает чаще.
Мы подробно рассмотрели две обязательных встречи по скраму — планирование и стендапы. В следующий раз поговорим об оставшихся двух — демо и ретроспективе.
Введение в скрам
— Проверено. Дать гению пять человек в подчинение, поставить четкую задачу и попросить организовать работу. Через неделю гений сам всё про себя поймет.
— Гений не поймет, он объяснит, какой народец некондиционный, читайте всё в блоге гения.
Баш
В прошлый раз я уже упоминал четыре принципа
Зачем нужен скрам
Скрам нужен, чтобы не получилось как в эпиграфе
Команда и спринты
Рабочая единица по скраму —
- команда разработки — профессионалы, совместных умений которых достаточно, чтобы делать продукт;
- владелец продукта — представитель бизнеса, знает текущее направление развития продукта, определяет приоритеты разработки;
скрам-мастер — проводит встречи, следит за соблюдением процесса, напоминает правила участникам, помогает улучшить рабочий процесс.
В команде разработки у всех одинаковая роль — «разработчик». У каждого разный опыт и уровень экспертизы, и это влияет на конкретный вид выполняемой работы. Но ответственность за результат у команды общая.
В идеале в команде разработки собраны все специалисты, необходимые для работы над продуктом: аналитики, дизайнеры, программисты, тестировщики. Взаимодействие в команде плоское. Размер команды не должен быть слишком большой, скажем, 5 — 9 человек, чтобы избежать излишних накладных расходов на взаимодействие.
В скраме нет менеджеров. Традиционные обязанности менеджера частично выполняет
Рабочий процесс по скраму делится на итерации — спринты. Команда разработки создает и в конце спринта поставляет заказчику некоторую завершенную функциональность — инкремент продукта.
Вот обязательные встречи в течение спринта, без которых у вас не будет скрама:
- планирование,
- ежедневный скрам («стендапы»),
- демонстрация новой функциональности заказчикам и пользователям
- ретроспектива.
Планирование
На планировании присутствует команда разработки и владелец продукта. Владелец продукта описывает потребности бизнеса на следующий спринт. Команда разработки определяет, успеет ли выполнить соответствующие задачи, и выбирает способ реализации. Также владелец продукта и команда разработки выбирают цель спринта.
Вот что написано о цели в руководстве:
Цель Спринта — это установленный для Спринта ориентир, который достигается посредством выполнения части Бэклога Продукта. Цель Спринта формулируется во время его Планирования и объясняет Команде Разработки, для чего создается Инкремент.
Цель Спринта обеспечивает Команде Разработки достаточную гибкость касательно объема функциональности, разрабатываемой в рамках Спринта. Цель Спринта воплощает важную смысловую нить, которая не только связывает выбранные элементы Бэклога Продукта, но и служит основанием для командной работы.
Цель связана с наиболее приоритетной задачей, но не тождественна ей. Польза выбора цели в дополнительной синхронизации ожиданий. Например, на планировании выясняется, что команда разработки скорее всего не может «сделать фичу и выложить в бой», потому что другая команда должна доработать АПИ, админы — запустить новый сервис и т. д. Но
У спринта должна быть только одна цель. Иногда после начала спринта возрастает оценка объема работ. В таких обстоятельствах команда разработки по согласованию с владельцем продукта жертвует менее приоритетными задачами, чтобы достичь цели. Если у спринта несколько целей, команде разработки непонятно, ради чего и чем жертвовать.
В следующий раз я расскажу о стендапах и о работе с задачами по скраму.
Исправляем баги с помощью рефакторинга
Василий Половнёв в советах рассказывает, как исправлять баги:
Сначала баг нужно повторить: найти последовательность действий, состояние или окружение, при котором баг повторяется. Без этого шага вы выкатите не исправление бага, а слепую догадку, которая вряд ли сработает, но точно
что-то сломает.Когда проблема гарантированно повторяется, можно приступать к изолированию: искать причину проблемы, генерируя и проверяя гипотезы, отрезая всё, не относящееся к проблеме.
Когда причина обнаружена, остаётся устранить баг и порефлексировать: что пошло не так, почему, как сделать так, чтобы в будущем таких багов не было.
Написано верно. Такому алгоритму и нужно следовать, исправляя баги. Но что делать, если баг воспроизвести нельзя? Я расскажу об одном таком баге, с которым пришлось бороться в CityAds.
Симптом
Бразильские вебмастеры жалуются, что при выводе заработанных денег не работает проверка
Попытка воспроизведения
Баг не повторяется ни на локальной копии сайта, ни на тестовых стендах, ни на российском сервере. Воспроизводится, только если напрямую зайти на бразильский сервер. Вышеприведенный алгоритм бессилен.
Изучение кода
К сожалению, в CityAds было много
$_SESSION['sms_codes'][$account_id]['code'] = $code;
$_SESSION['sms_codes'][$account_id]['time'] = time();
$_SESSION['sms_codes'][$account_id]['amount'] = $amount;
Работа с тремя элементами массива происходила несколько раз. Каждый раз три строчки копировались и немного изменялись. Например, при генерировании нового кода очищался один элемент, а не все три.
Говнокод плох тем, что он «одноразовый». Его просто написать, но сложно понимать и изменять.
Логирование
Когда баг нельзя воспроизвести локально, может помочь логирование. Чтобы понять, почему код работает не так, как ожидается, вы добавляете инстуркции для записи значений переменных в лог, например, в файл. Логировать полезно не все действия подряд, а только определенные, например, с вашего
Я залогировал значения переменных и увидел, что к моменту проверки кода в сессии было пусто, как будто код вообще не генерировался. Тем не менее, другие значения, не связанные с
Гипотеза
Мне было ясно, что причина бага связана с хранением данных в разделяемой памяти. Я предположил, что между генерированием и проверкой
Я решил не искать, кто именно портит данные в сессии, а с нуля переписать обработку
Рефакторинг
К этому времени мы подключили Symfony и писали новый код по принципам SOLID. Я написал сервис, в котором инкапсулировал логику работы с
Переписанный код сразу заработал как нужно. После выкладки оказалось, что проблема на бразильском сервере исчезла.
Ссылки по теме
- Подробности о переходе от императивного кода к объектному, SOLID, DTO, DI в скринкасте по рефакторингу с помощью PHP Storm
- Еще одна байка из CityAds на хабре: PHP, статические переменные внутри методов класса и история одного бага
Промышленное программирование и область ответственности разработчика
Промышленное прогаммирование
Хочу поделиться опытом промышленной разработки программного обеспечения. Под словом «промышленная» я понимаю разработку приносящего деньги продукта в коллективе от нескольких десятков человек.
Между промышленной разработкой продукта и любительским программированием разница такая же, как между игрой в футбол во дворе и выступлением на чемпионатах. К этой разнице отсылает фраза «делаю продукт, а не код» на главной странице этого сайта.
Вряд ли я смогу рассказать специалистам
Аджайл-манифест разработки программного обеспечения
Начнем систематизировать знания о разработке с
Люди и взаимодействие важнее процессов и инструментов.
Работающий продукт важнее исчерпывающей документации.
Сотрудничество с заказчиком важнее согласования условий контракта.
Готовность к изменениям важнее следования первоначальному плану.То есть, не отрицая важности того, что справа, мы
всё-таки больше ценим то, что слева.
Это емкие, многогранные принципы. Мы к ним еще не раз вернемся. А пока посмотрим на одну составляющую первого принципа, а именно на то, как организуют взаимодействие с разработчиком.
Область ответственности разработчика
Недавно на хабре вышла статья про то, как Слак и мессенджеры вообще снижают продуктивность. В комментариях завязалась интересная побочная дискуссия. Первая точка зрения:
Никто никого не должен отвлекать по пустякам, вообще обычный разработчик должен в рабочее время заниматься только выполнением текущих запланированных задач и реагировать только на два типа сообщений:
1. Авария —что-то серьезное на продакшене или ошибка на уровне архитектуры, в первом случае срочно чиним, во втором останавливаемся и обсуждаем т.к. дальнейшая работа может просто оказаться бессмысленной. Если часто проблемы с продом — это чаще всего косяк тестировщиков, если хреново спланирована архитектура или выбраны не те инстументы — косяк архитекторов.
2. Блокировка — т.е. отсутствие реакции на это сообщение реально блокирует работу другого человека. Если есть большой поток блокирующих сообщений, то это либо отсутствие компетенции у других исполнителей — косяк того кто их нанял, либо хреновое планирование и распределение задач между исполнителями — косяк ПМа.Если же разработчик вынужден по работе напрямую общаться с кем либо кроме ПМа и других разработчиков (например с заказчиками), то ему лучше сменить место работы!
Минус подобных разработчиков в том, что они реально хорошо работают только если все тщательно спланировано. в критической же ситуации они теряются и оказываются абсолютно неспособны срочно решить внезапную проблему.
…
Я хочу получать удовольствие от своей работы, я хочу того самого пресловутого творчества, новых идей и всего такого. если я не вовлечен в процесс, не принимаю участия в обсуждениях и просто плыву по течению бездумно делая что мне написали в тикет — какое от этого удовольствие? какое от этого ощущение своего вклада в итоговый продукт?
Это два противоположных подхода к вопросу об области ответственности разработчика. Давайте выделим особенности каждого подхода:
| Оператор ЭВМ | Инициативный разработчик |
| Просит четкое техническое задание | Просит объяснить |
| Делает по требованиям, даже если они противоречат сделанному ранее | Не любит переделывать При обнаружении противоречий сообщает постановщику задачи |
| Не дает результат без менеджера и тестировщиков | Работает самостоятельно Знает, что значит «сделать» |
| Получает меньше денег | Получает больше денег |
Мне близок второй способ. При обсуждении с заказчиками больше возможностей решить задачу меньшими усилиями, иногда даже вообще без написания нового кода. Или, поняв проблему, отговорить от создания костыля и предложить полезную функцию.
Руководитель программистов должен учитывать при подборе и огранизации рабочего процесса особенности каждого способа. Первый свойственен водопадной модели, воторй — аджайлу. Если вы нанимаете инициативных разработчиков — готовьте бюджет. Если нанимаете операторов ЭВМ, нанимайте еще менеджеров и тестировщиков.
Программирование ≠ информатика
На хабре перевод статьи некоего Коннелла о том, почему нельзя до конца формализовать и алгоритмизировать разработку софта:
Разработка программного обеспечения никогда не будет строгой дисциплиной с подтверждёнными результатами, поскольку в неё вовлечена деятельность человека.
Это
экстра-математическое утверждение о границах формальных систем. Я не имею никаких доказательств за или против. Но факт в том, что человеческие проблемы остаются центральными вопросами разработки программного обеспечения:
- Что должна делать эта программа? (требования, юзабилити, безопасность)
- Как должна выглядеть программа внутри, чтобы её легко было починить и модифицировать? (архитектура, дизайн, масштабируемость, переносимость, расширяемость)
- Как долго займёт её написание? (оценка)
- Как мы должны её разрабатывать? (кодирование, тестирование, измерение, конфигурация)
- Как следует эффективно организовать работу команды? (менеджмент, процесс, документация)
Все эти проблемы вращаются вокруг людей.
Мой тезис объясняет, почему разработка ПО настолько трудная и такая скользкая. Проверенные методы одной команды программистов не работают для других команд. Исчерпывающий анализ прошлых проектов может быть бесполезен для хорошей оценки следующего. Каждый из революционных инструментов разработки помогает по
чуть-чуть, а затем не соответствует своим великим обещаниям. Причина в том, что люди слишком мягкие, разочаровывающие и непредсказуемые.
Как улучшить legacy-код
Статья на хабре «Как улучшить
Разрушаем мифы о PhpStorm
Илья Бирман написал о редакторах и средах разработки:
Я много лет использовал редактор кода«Сублайм-текст». Он не дотягивал по функциональности даже до «Эдитплюса», которым я пользовался на Винде больше десяти лет назад, но казался мне самым приятным и продвинутым из того, что есть на Маке. Всякие ИДЕ я не рассматривал — они уродские и тормозные. Однажды я видел, как разработчик переименовывал файл в «ПХПШторме». На экране несколько секунд заполнялся прогрессбар. Нет, спасибо.
Давайте я тоже поддержу межблоговые дискуссии и отвечу Илье. А ответить есть что.
Уже лет 5 я использую PhpStorm как один из основных инструментов. Как такое могло произойти, если среды разработки — уродские и тормознутые? Давайте разбираться.
Переход на PhpStorm
Раньше я программировал в Notepad++. Вершина его функций — поиск и замена по всем файлам в папке. Казалось, этого вполне достаточно. Мне тоже нравилась скорость работы редактора, и я тоже относился к IDE снисходительно. «Я и так знаю названия функций, нахрена мне тормознутая подсветка синтаксических ошибок в коде?»
Я не помню, что заставило меня скачать PhpStorm. Мне могли понадобиться
Тем не менее, PhpStorm у меня прижился. Как автор опенсорсного продукта — движка S2 — я получил бесплатную лицензию. С тех пор PhpStorm стал одним из основных моих инструментов.
Миф №1: PhpStorm тормозит
PhpStorm как IDE отличается от текстовых редакторов:
- индексирует файлы проекта, чтобы потом мгновенно искать по ним, не перебирая каждый раз содержимое;
- распознает контекст: понимает, где названия функций, где локальные переменные, где пути к файлам и т. д.
PhpStorm как редактор не хуже Notepad++. С той же скоростью появляются буквы и перемещается курсор. Поиск работает мгновенно за счет индексации. Анализ кода работает в фоне и может отставать от курсора. Но в этом большой проблемы нет, потому что сначала программист пишет код, а потом смотрит на подсказки среды разработки.
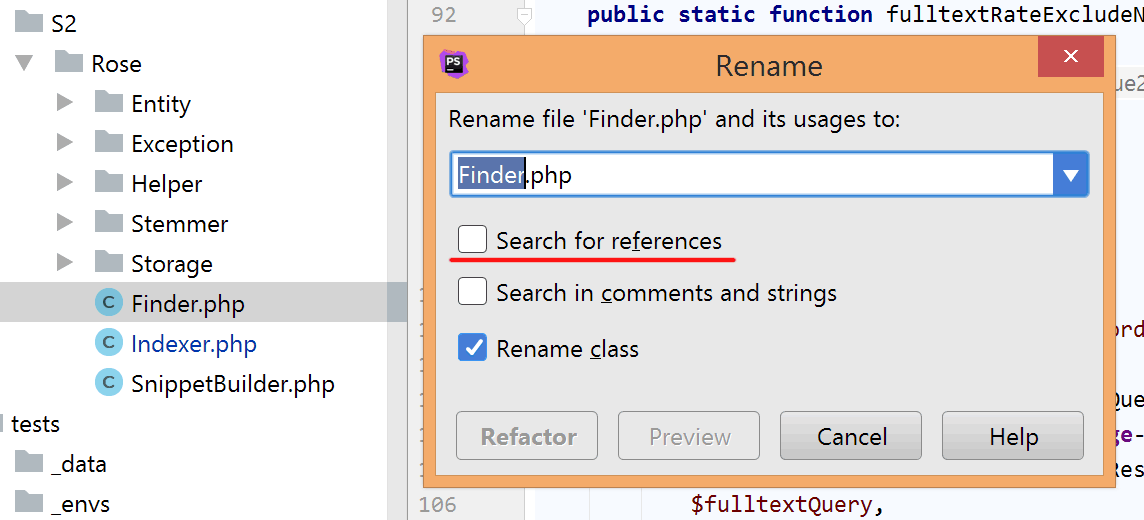
Миф №2: переименование файла занимает в PhpStorm несколько секунд с прогресс-баром
Зависит от того, что нужно программисту. PhpStorm способен искать вхождения старого названия файла по всему проекту и по контексту определять, нужно ли это название изменить. Альтернатива в обычных редакторах — поиск и замена по всем файлам — занимает несколько минут рутинной работы. Экономия времени на два порядка.
Поиск старого названия файла можно отключить прямо в окне переименования. Тогда файл переименовывается мгновенно.
Миф №3: PhpStorm «устанавливать и настраивать год»
Установка проходит не сложнее установки любых других программ. Первоначальной настройки PhpStorm не требует. Может открыть любую папку как проект без предварительных вопросов.
Настройку дополнительных инструментов делаете тогда, когда они вам понадобятся:
- путь к git.exe для работы с гитом;
- доступ к БД, чтобы делать запросы из среды разработки;
- доступ на сервер по SSH/FTP для загрузки файлов проекта.
Пошаговая отладка через Xdebug настраивается сложнее
Миф №4: PhpStorm «выглядит как говно»
Вкусовщина, конечно. Нормально он выглядит. Внешний вид работать не мешает. Чтобы не приводить зря громадный скриншот, покажу заодно «git blame»:
В следующий раз я расскажу о возможностях сред разработки на примере PhpStorm, которых нет в редакторах, но которые повышают продуктивность работы за счет автоматизации рутины.
Современный рынок труда
Сегодня за обедом разговаривали с коллегой:
— Я чувствую спрос на себя как на программиста, а как на физика — не чувствую.
— И это в стране, первой запустившей человека в космос.
Закомментированный код
Я всегда с недоверием отношусь к закомментированным строкам кода в исходниках программ. Действительно, встретив в коде закомментированные части, думаешь, или это неработающий вариант, который был позднее переписан, а старый вариант не удален. Или это недописанный новый вариант взамен старого. Или это часть кода, которая была закомментирована для ограничения функциональности.
Участки кода в комментариях — удобный прием при отладке. В окончательной версии в комментариях должны оставаться только пояснения.